How Apache Kylin Query Work(三)
本文最后更新于:2025年1月23日 下午
FYI
- repo:https://github.com/apache/kylin
- branch:kylin5
- commitMessage:Merge pull request #2245 from VaitaR/patch-1
- commitID:e18b73ab6a6ed66de41532bc03373e8efeff0b77
Concepts
Basic
Table - 源数据表。在创建模型并加载数据之前,系统需要从数据源(通常为 Hive)同步表的元数据,包含表名、列名、列属性等。
Model - 模型,也是逻辑语义层。模型是一组表以及它们间的关联关系 (Join Relationship)。模型中定义了事实表、维度表、度量、维度、和一组索引。模型和其中的索引定义了加载数据时要执行的预计算。系统支持基于星型模型 和 雪花模型 的多维模型。
Index - 索引,在数据加载时将构建索引,索引将被用于加速查询。索引分为聚合索引与明细索引。
- Aggregate Index - 聚合索引,本质是多个维度和度量的组合,适合回答聚合查询,比如某年的销售总额。
- Table Index - 明细索引,本质是大宽表的多路索引,适合回答精确到记录的明细查询,比如某用户最近 100 笔交易。
Load Data - 加载数据。为了加速查询,需要将数据从源表加载入模型,在此过程中也将构建索引,整个过程即是数据的预计算过程。每一次数据加载将产生一个 Segment,载入数据后的模型可以服务于查询。
- Incremental Load - 增量数据加载。在事实表上可以定义一个分区日期或时间列。根据分区列,可以按时间范围对超大数据集做增量加载。
- Full Load - 全量加载。如果没有定义分区列,那么源表中的所有数据将被一次性加载。
- Build Index - 重建索引。用户可以随时调整模型和索引的定义。对于已加载的数据,其上的索引需要按新的定义重新构建。
Segments - 数据块。是模型(索引组)经过数据加载后形成的数据块。Segment 的生成以分区列为依据。对于有分区列的模型(索引组),可以拥有一个或多个 Segment,对于没有分区列的模型(索引组),只能拥有一个 Segment。
OlapContext
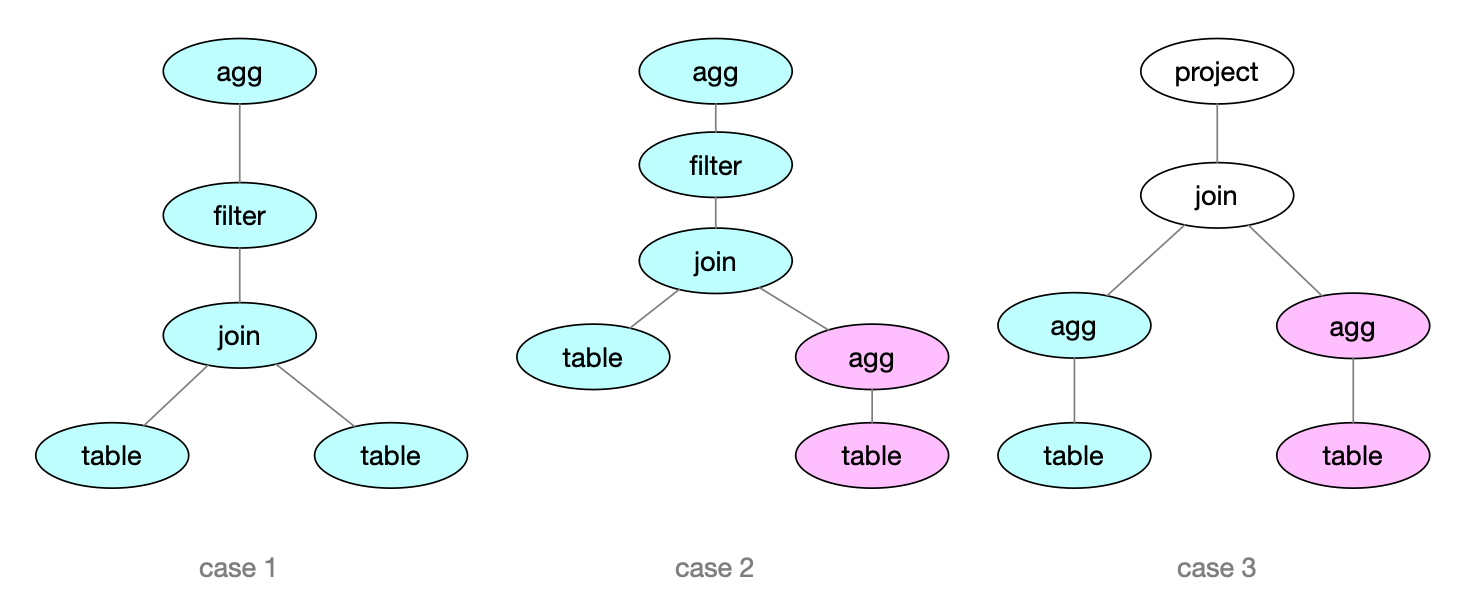
SQL 进入 Kylin 中经过 Calcite 解析转换、优化后形成一棵树结构的查询逻辑计划 RelNode,这种结构是 Calcite 在逻辑层的一种表示,比较典型的 RelNode 树结构如下图 case1 所示。
如果再加上 RelNode 的详细信息,绝大多数场景下可以将这棵树重新翻译成原始 SQL,但这种结构无法直接作用于 Kylin 的预计算,因此 Kylin 定义了一种可以预计算的数据结构,这种结构称之为 OlapContext,它能够同时对应 RelNode 和 Kylin 匹配的模型索引。
需重点关注的属性
firstTableScan: OlapContext 用到的第一张表(通常指事实表)allTableScans: 使用到的所有表信息aggregations: 查询的度量算子filterColumns: 过滤条件(SQL where 条件的列或者表达式)joins: 表与表的 join 关系sql: 生成 OlapContext 的原始 SQL,一条 SQL 可能会被切分成多个 OlapContexttopNode: OlapContext 最顶端的 RelNode 节点expandedFilterConditions: 记录查询用到的过滤表达式,以支持后面做过滤优化
除此之外还有一些别的属性需要留意
parentOfTopNode: 一般为 null 除非 JoinRel 被切分开innerGroupByColumns、innerFilterColumns: 推荐可计算列时使用到sortColumns: 排序列
总结一下,OlapContext 记录了整个 Kylin 模型匹配的上下文信息,是最核心的数据结构,对这块熟悉可以更好地理解索引匹配流程。
OlapRel
Kylin 继承自 Calcite 实现的抽象接口类,定义了遍历整个查询阶段所需上下文及遍历方式,需关注的属性和方法
getColumnRowType: 记录了原始表类型和 Kylin 模型中列数据类型的对应关系implementOlap: 子类需实现的遍历方法,包含建立和原始表的对应关系,收集 OlapContext 的信息都会在这个方法中完成,是很重要的方法implementRewrite: 在完成模型匹配之后,基于情况对查询逻辑计划树进行重建implementEnumerable: 适配 Calcite EnumerableConvention 物理执行引擎的 Java 实现implementContext: 分配 OlapContext 的逻辑方法,一个完整的查询逻辑计划可能会划分成多个 OlapContextimplementCutContext: 如果 OlapContext 切分得太大无法匹配模型索引,则会尝试对其再次切分
Model Match
入口: QueryContextCutter#selectRealization
整体流程图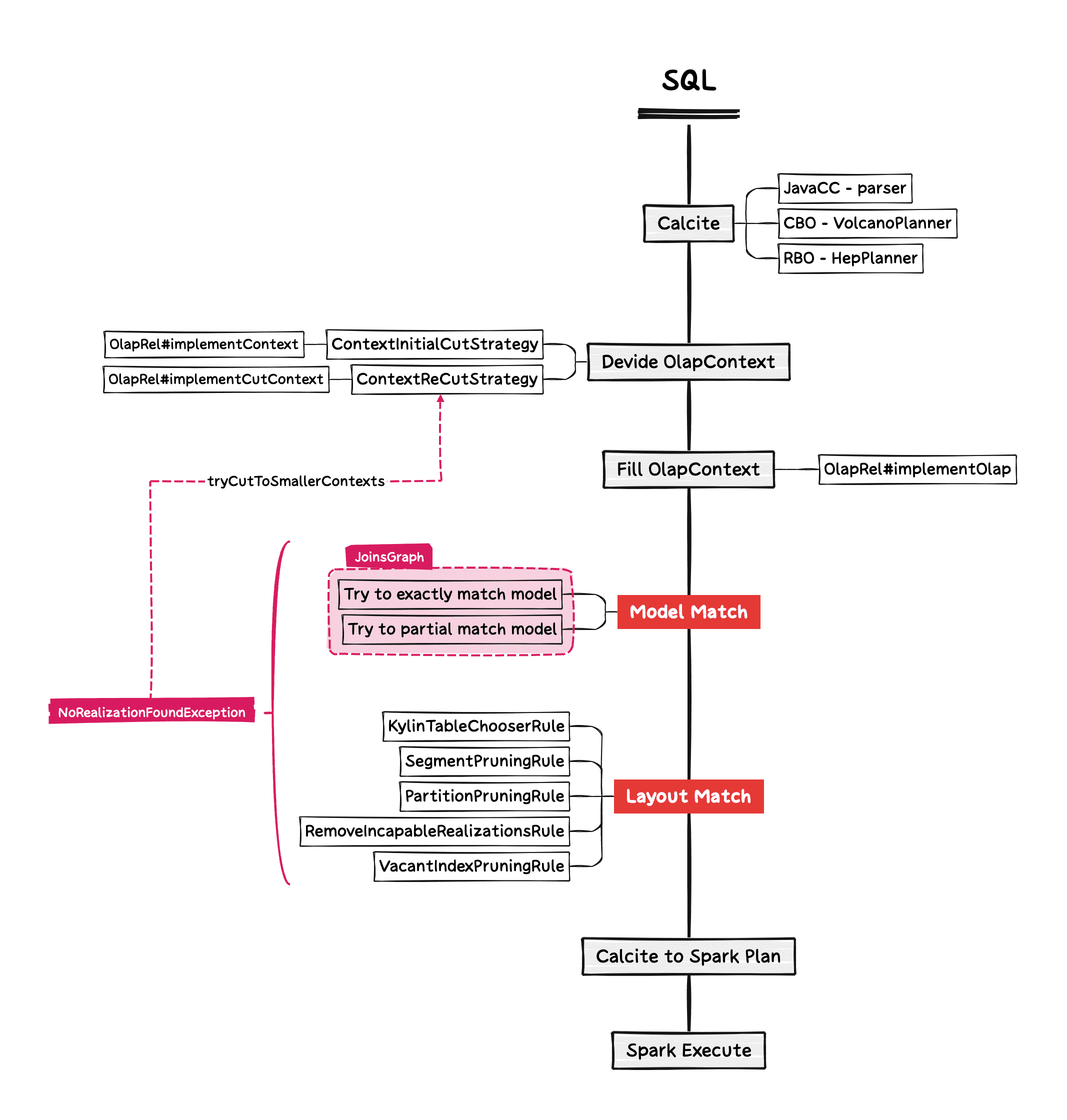
1. Divide OlapContext
OlapContext 的划分和分配在选出最优的查询逻辑计划之后,匹配模型索引之前。
一个基本的规则是遇到 agg 就划分出一个 OlapContext,如 OlapContext 示例图的 case1,从 agg 往下遍历时没有其他的 agg,当前查询逻辑计划树就只会分配一个 OlapContext,同理,case2 和 case3 会划分出两个 OlapContext。
每个 OlapContext 代表着模型索引的最小匹配单元,在划分后,将 OlapContext 与模型索引进行匹配,当无法匹配时,会将大的 OlapContext 再次切分成小的进行匹配,直到达到最大尝试切分的匹配次数,默认是 10,可通过项目级参数进行配置。
划分 OlapContext 主要通过下面两个类
ContextInitialCutStrategy- 遍历查询逻辑计划树,接着通过子类实现的
OlapRel#implementContext方法划分 OlapContext - 如果还有未分配的表,会为其直接分配 OlapContext
- 遍历查询逻辑计划树,接着通过子类实现的
ContextReCutStrategy- 主要逻辑是将大的 OlapContext 切小尽可能匹配模型索引,接着通过子类实现的
OlapRel#implementCutContext方法划分 OlapContext
- 主要逻辑是将大的 OlapContext 切小尽可能匹配模型索引,接着通过子类实现的
划分逻辑相对复杂的子类是 OlapJoinRel,先访问 leftChild,再访问 rightChild,最后在当前节点上分配 OlapContext。
2. Fill OlapContext
通过后序遍历的方式对先前压入栈的查询逻辑计划节点填充 OlapContext 信息,上面第一段逻辑是基于查询逻辑计划切分出 OlapContext,然而还需要在查询节点上收集必要的 OlapContext 信息,通过每个子类实现的 OlapRel#implementOlap 方法进行填充。
3. Choose Candidate
默认通过多线程的方式来选择匹配合适的索引,使用 CountDownLatch,输入是 Context 划分的数量。也可以通过项目级参数配置不使用多线程的方式匹配索引,串行执行。
3.1 Attempt Select Candidate
3.1.1 Filter qualified models by firstTable of OlapContext
基于 OlapContext 第一张表即事实表来筛选出待匹配的模型,每个 Project 都保存了对应的模型信息缓存在内存中,取出的操作是比较快的,取出后再过滤掉不符合条件的模型。
- 移除没有准备好 Segments 的模型
- 用户通过 SQL hint 的方式指定了模型匹配的优先级,未指定的模型会被移除
3.1.2 Match model
先检查是否有待匹配模型,没有的话直接抛出异常,等待下次重试。模型匹配采用的是图匹配方式,参考类: JoinsGraph
需关注属性
center: 表示图的中心表(通常是查询的主表),类型为TableRef。vertexMap: 存储所有表的别名与表引用TableRef的映射关系,类型为Map<String, TableRef>。vertexInfoMap: 存储每个表TableRef的顶点信息,包括该表的出边outEdges和入边inEdges,类型为Map<TableRef, VertexInfo<Edge>>。edges: 存储图中所有的边Edge,类型为Set<Edge>。
需关注方法match: 将当前图与一个模式图pattern进行匹配,返回是否匹配成功。匹配过程中会生成一个别名映射表matchAliasMap,用于记录两个图中表的对应关系。match0: 匹配的核心逻辑,递归地匹配图中的表和边。findOutEdgeFromDualTable: 在模式图中查找与查询图匹配的边。normalize: 对图进行规范化处理,将某些左连接LEFT JOIN转换为左或内连接LEFT OR INNER JOIN,以便优化查询,需要通过额外的参数配置。
3.1.2.1 Try to exactly match model
通过图匹配的方式对 OlapContext 中的事实表和join 关系与模型上的表和 join 关系等进行对比,检查其是否一一对应,如果都能匹配上,那么就可以说当前模型的索引是能够精确匹配查询 SQL 的。
OlapContex 中的表信息是从查询 SQL 的逻辑计划树中收集的。
3.1.2.2 Try to partial match model
在精确匹配未找到合适模型的情况下,会基于配置参数再尝试部分匹配模型,这里的部分指的是仅匹配部分 join 关系。
3.1.2.3 Lauout Match - Select Realizations
在已经选出合适的 layout 之后,会继续对候选的索引进行筛选,陆续应用以下 Rules
KylinTableChooserRule: 匹配模型索引(分为明细索引和聚合索引,需要所有的列和聚合算子都能匹配上,默认不会用明细索引回答聚合查询,可通过参数配置)SegmentPruningRule: 根据分区列和 Filter 条件对 Segment 进行裁剪PartitionPruningRule: 根据多级分区列筛选分区RemoveIncapableRealizationsRule: 选择成本最低的 layoutVacantIndexPruningRule(optional): 选择空的 layout 回答查询
layout 指的是代码层面的抽象索引(包含多种维度和度量的组合),其实就是 Index。
3.1.3 Find the lowest-cost candidate
对所有选出的 layout 应用排序规则后取出最优的回答查询,有时候不一定是成本最低的,比如用户某些场景的特殊需求下,成本最低的 layout 的索引数据是不完整的,Kylin 首先需要保证查询数据的完整性。
至此,模型匹配的逻辑已经讲述完毕。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!