How Apache Kylin Query Work(二)
本文最后更新于:2025年1月23日 下午
FYI
全文仅关注逻辑主体代码,其他代码均省略。
- repo:https://github.com/apache/kylin
- branch:kylin5
- commitMessage:KYLIN-5943 Upgrade spark to 3.3.0-kylin-4.6.26.0
- commitID:77201e7bcddb605da56e7f00d39db82e8f2d8931
Query Entrance
我们跳过其他部分,直接进入 Kylin 查询真正处理的核心入口 QueryExec#executeQuery。
public QueryResult executeQuery(String sql) throws SQLException {
RelRoot relRoot = sqlConverter.convertSqlToRelNode(sql);
RelNode node = queryOptimizer.optimize(relRoot).rel;
QueryResult queryResult = new QueryResult(executeQueryPlan(postOptimize(node)), resultFields);
}Calcite
在模型匹配前的查询逻辑都是在 Calcite 中进行处理的。
Prepare
这一过程为后续 Calcite 的元数据 Schema 以及查询阶段使用的优化规则做了准备,参考 QueryExec 的构造方法
public QueryExec(String project, KylinConfig kylinConfig, boolean allowAlternativeQueryPlan) {
this.project = project;
this.kylinConfig = kylinConfig;
connectionConfig = KylinConnectionConfig.fromKapConfig(kylinConfig);
schemaFactory = new ProjectSchemaFactory(project, kylinConfig);
rootSchema = schemaFactory.createProjectRootSchema();
String defaultSchemaName = schemaFactory.getDefaultSchema();
catalogReader = SqlConverter.createCatalogReader(connectionConfig, rootSchema, defaultSchemaName);
planner = new PlannerFactory(kylinConfig).createVolcanoPlanner(connectionConfig);
sqlConverter = QueryExec.createConverter(connectionConfig, planner, catalogReader);
dataContext = createDataContext(rootSchema);
planner.setExecutor(new RexExecutorImpl(dataContext));
queryOptimizer = new QueryOptimizer(planner);
}注意这里的 planner 是 Kylin 在 CBO 阶段用到的优化规则,包含 Calcite 默认提供的一些优化规则,以及 Kylin 自己实现的优化规则,需要说明的是 Kylin 通过 CBO 阶段将 Calcite 通过 Schema 校验后的查询逻辑计划首先转变为自定义的 Olap Convension 逻辑计划,这之后还会经过一次 RBO 阶段优化才会转为可执行的物理执行计划。
public VolcanoPlanner createVolcanoPlanner(CalciteConnectionConfig connectionConfig) {
VolcanoPlanner planner = new VolcanoPlanner(new PlannerContext(connectionConfig));
registerDefaultRules(planner);
registerCustomRules(planner);
return planner;
}Kylin 在 CBO 阶段自定义 Rule 大多继承自 Calcite ConverterRule,该抽象类的定义是在不改变语义的情况下,将一种调用约定 Convension 转换为另一种 Convension,如 Kylin 中从默认的 NONE -> OLAP,转换时一般是伴随的关系,如 Kylin 中 OlapProjectRule 将 LogicalProject 转换为 OlapProjectRel,这样就可以在后续对 OlapProjectRel 继续进行转换优化,LogicalXxx 是 Calcite 通过校验后未经优化的查询逻辑计划。
当 Calcite 执行 CBO 优化完成后,会检查当前查询逻辑计划中是否仍有 NONE 的 RelNode,如果有则说明优化转换没有覆盖到,此时会报错,比如下面就是超过了 CBO 最大重试次数后 LogicalSort 未能成功转换的报错信息。
There are not enough rules to produce a node with desired properties: convention=ENUMERABLE, sort=[0 ASC-nulls-first].
Missing conversion is LogicalSort[convention: NONE -> ENUMERABLE]SQL -> AST -> RelRoot
对应前文的 sqlConverter.convertSqlToRelNode(sql) 逻辑,这一段首先将 SQL 转换为一棵抽象语法树 AST,Calcite 使用的是 JavaCC,Spark 使用的是 Antlr。
public RelRoot convertSqlToRelNode(String sql) throws SqlParseException {
SqlNode sqlNode = parseSQL(sql);
return convertToRelNode(sqlNode);
}转换时涉及到词法分析、语法分析,编写模板是 parser.jj 文件,可以通过在文件中新增定义实现并支持自己的语法。
SQL 转换为 SqlNode 之后长这样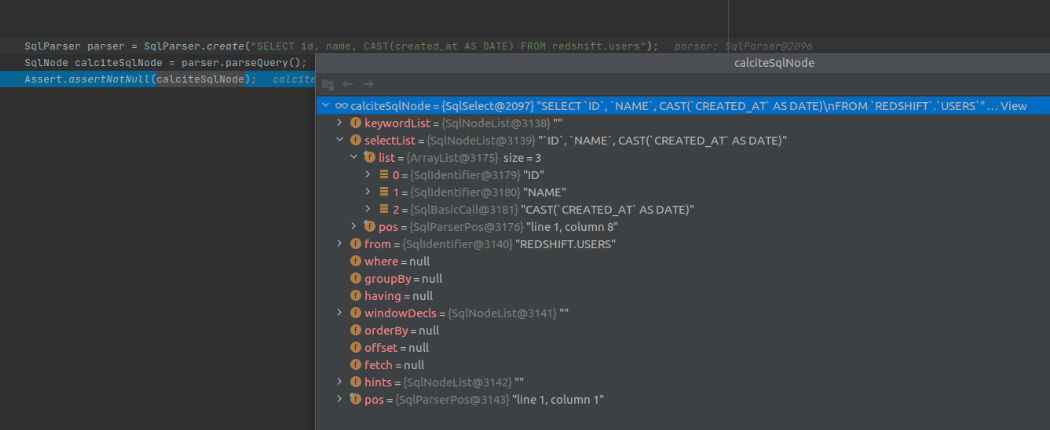
接着经过一系列的校验以及和元数据信息的绑定,就可以从一棵抽象语法树 AST 变成未经优化的逻辑计划 RelRoot,RelRoot 是一系列查询逻辑计划节点 RelNode 的根节点。
private RelRoot convertToRelNode(SqlNode sqlNode) {
RelRoot root = sqlToRelConverter.convertQuery(sqlNode, true, true);
return root;
}元数据信息在 Calcite 中称为 Schema,有个抽象类 AbstractSchema,Kylin 的 OlapSchema 继承并实现了该抽象类,这些信息在创建出 sqlConverter 前需要先准备好。
CBO
我们来看这一段 queryOptimizer.optimize(relRoot),从这里就开始了对查询逻辑计划的优化操作。
这一块包含多处子步骤优化,列举如下
- subQuery
- DecorrelateProgram
- TrimFieldsProgram
- program1
- calc
subQuery
Calcite 原生仅有 3 个优化规则,Kylin 在此基础上新增了 OLAPJoinPushThroughJoinRule 和 OLAPJoinPushThroughJoinRule2,这两个规则均改自 Calcite 原生的 JoinPushThroughJoinRule,目的是将带有 join 的子查询下推至表与表的 join 查询逻辑之后,这样方便 Kylin 在使用查询逻辑计划匹配模型时能够匹配上预定义的表 join 关系,OLAPJoinPushThroughJoinRule2 则在此基础上允许循环匹配,需要说明的是 Kylin 创建模型定义的表 join 关系只有 left 和 inner 两种,当 SQL 查询为 right join 时不会作此改写。
- CoreRules.FILTER_SUB_QUERY_TO_CORRELATE
- CoreRules.PROJECT_SUB_QUERY_TO_CORRELATE
- CoreRules.JOIN_SUB_QUERY_TO_CORRELATE
以一条 SQL 举例说明子查询的可读性,比如查询没有订购物品的消费者信息
SELECT c.c_custkey
FROM customer c
LEFT JOIN orders o ON c.c_custkey = o.o_custkey
WHERE o.o_custkey IS NULL;使用子查询的方式改写如下,极大地降低了 SQL 的复杂性
SELECT c_custkey
FROM customer
WHERE NOT EXISTS (
SELECT *
FROM orders
WHERE o_custkey = c_custkey
)在查询逻辑计划中将连接外部查询和子查询的运算符称为 Correlate,Calcite 通过这些规则将用户写的子查询 SQL 改写为上面的 SQL 在后续逻辑进行处理,这样做更便于进行查询逻辑计划优化。
DecorrelateProgram
这一部分和上面消除子查询的优化相互关联,这一过程称为去相关或取消嵌套,去相关的关键是获得子查询的外部查询对应列值。当相关连接算子的左右子树没有相关列时,可以将 Correlate join 转换为普通的 join,参考下图,这样就可以像之前一样从下到上进行计算。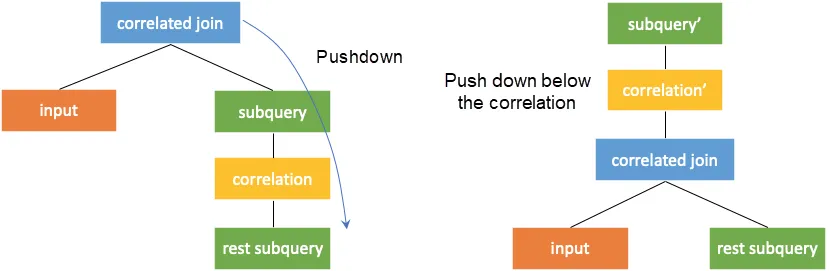
还有转换为带有 condition 的 Correlate join,参考下图。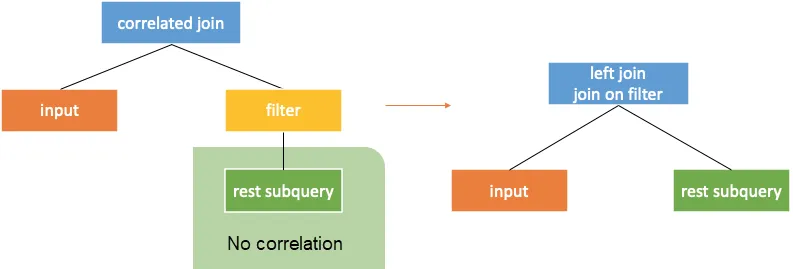
还有很多其他转换思路,这里不再一一举例。
TrimFieldsProgram
该过程无法通过参数控制,其主要作用是裁剪关系表达式中用不到的字段,在创建新的 RelNode(Calcite 中定义的查询逻辑计划类比 Spark Logical Plan) 同时,也会进行必要的优化,比如对 Filter 条件表达式进行优化,参考如下方法,Calcite 会尝试对表达式进行各种优化:布尔表达式是否返回值始终为 false、常量值是否能直接计算(这部分会进一步使用 RexExecutable 调用 JDK 底层方法直接生成可执行代码)等。
// RelFieldTrimmer#trimFields(Filter, ImmutableBitSet, Set<RelDataTypeField>)
public TrimResult trimFields(
Filter filter,
ImmutableBitSet fieldsUsed,
Set<RelDataTypeField> extraFields) {
// If the input is unchanged, and we need to project all columns,
// there's nothing we can do. if (newInput == input
&& fieldsUsed.cardinality() == fieldCount) {
return result(filter, Mappings.createIdentity(fieldCount));
}
// Build new filter with trimmed input and condition.
relBuilder.push(newInput)
.filter(filter.getVariablesSet(), newConditionExpr);
// The result has the same mapping as the input gave us. Sometimes we
// return fields that the consumer didn't ask for, because the filter
// needs them for its condition.
return result(relBuilder.build(), inputMapping);
}program1
接下来就到了执行 planner 中预定义好的优化规则这一步,由于前文创建的是 VolcanoPlanner,直接看 VolcanoPlanner#findBestExp 方法。
@Override public RelNode findBestExp() {
ensureRootConverters();
registerMaterializations();
ruleDriver.drive();
RelNode cheapest = root.buildCheapestPlan(this);
return cheapest;
}ruleDriver.drive() 是这段逻辑的核心,而 buildCheapestPlan 是将每个逻辑计划中最优也就是代价最低的查询逻辑计划选出来,继续往下分析 drive 方法。
执行优化匹配时,依次从 ruleQueue 中弹出一条优化规则,首先检查是否符合 matches 的判断条件(默认返回 true),满足条件时再调用优化规则的 onmatch 方法进行处理,onmatch 内部的逻辑涉及优化规则具体的优化步骤和规则对优化前后查询逻辑计划的转换。canonize 方法用于保证始终返回当前查询逻辑计划的根节点。至于计算 cost 并选出 best 查询节点 RelNode 的过程则是在 VolcanoPlanner#setRoot 中进行的,这里均不展开细讲。
@Override public void drive() {
while (true) {
assert planner.root != null : "RelSubset must not be null at this point";
LOGGER.debug("Best cost before rule match: {}", planner.root.bestCost);
VolcanoRuleMatch match = ruleQueue.popMatch();
if (match == null) {
break;
}
assert match.getRule().matches(match);
try {
match.onMatch();
} catch (VolcanoTimeoutException e) {
LOGGER.warn("Volcano planning times out, cancels the subsequent optimization.");
planner.canonize();
break;
}
// The root may have been merged with another
// subset. Find the new root subset.
planner.canonize();
}
}这时可能有人会疑问,为什么继承了抽象类 RelOptRule 实现自定义的优化规则,在没有重载 matches 方法的情况下,优化规则却没有匹配进入呢?这是个非常好的问题,和注册优化规则时的逻辑有关系,我们回过头关注一下其构造方法。重点关注变量 RelOptRuleOperand,在传参时甚至会校验该变量值不能为 null。
protected RelOptRule(RelOptRuleOperand operand,
RelBuilderFactory relBuilderFactory, @Nullable String description) {
this.operand = Objects.requireNonNull(operand, "operand");
}结合 RelOptRuleOperand 的 matches 方法和 Kylin 中一个具体的优化规则 OlapAggProjectMergeRule 来举例。
public boolean matches(RelNode rel) {
if (!clazz.isInstance(rel)) {
return false;
}
if ((trait != null) && !rel.getTraitSet().contains(trait)) {
return false;
}
return predicate.test(rel);
}下面这段是 OlapAggProjectMergeRule 涉及到的方法,可以看到其构造方法传给父类时的 RelOptRuleOperand 包含了多个 RelNode 之间的关系,比如查询逻辑计划符合 agg-project-join 或是 agg-project-filter-join 这样的操作顺序,当触发优化规则执行时,不符合这一条件的优化规则首先就被过滤掉了。
public class OlapAggProjectMergeRule extends RelOptRule {
public static final OlapAggProjectMergeRule AGG_PROJECT_JOIN = new OlapAggProjectMergeRule(
operand(OlapAggregateRel.class, operand(OlapProjectRel.class, operand(OlapJoinRel.class, any()))),
RelFactories.LOGICAL_BUILDER, "OlapAggProjectMergeRule:agg-project-join");
public static final OlapAggProjectMergeRule AGG_PROJECT_FILTER_JOIN = new OlapAggProjectMergeRule(
operand(OlapAggregateRel.class,
operand(OlapProjectRel.class, operand(OlapFilterRel.class, operand(OlapJoinRel.class, any())))),
RelFactories.LOGICAL_BUILDER, "OlapAggProjectMergeRule:agg-project-filter-join");
public OlapAggProjectMergeRule(RelOptRuleOperand operand, RelBuilderFactory relBuilderFactory, String description) {
super(operand, relBuilderFactory, description);
}
}calc
这一过程比较特殊,属于可执行的优化规则(指 Convension 由 NONE -> BindableConvention),见 RelOptRules#CALC_RULES ,其顺序如下。执行时同样先检查是否符合优化规则匹配条件,再执行优化操作。
HepPlanner#findBestExp -> HepPlanner#executeProgram(HepProgram) -> RuleInstance.State#execute -> HepPlanner#applyRules -> HepPlanner#applyRuleRBO
经过一系列 CBO 阶段优化规则之后,来到了 RBO 阶段,直接看代码逻辑,见 HepUtils.runRuleCollection。
public List<RelNode> postOptimize(RelNode node) {
Collection<RelOptRule> postOptRules = new LinkedHashSet<>();
// It will definitely work if it were put here
postOptRules.add(SumConstantConvertRule.INSTANCE);
if (kylinConfig.isConvertSumExpressionEnabled()) {
postOptRules.addAll(HepUtils.SumExprRules);
}
if (kylinConfig.isConvertCountDistinctExpressionEnabled()) {
postOptRules.addAll(HepUtils.CountDistinctExprRules);
}
if (kylinConfig.isAggregatePushdownEnabled()) {
postOptRules.addAll(HepUtils.AggPushDownRules);
}
if (kylinConfig.isScalarSubqueryJoinEnabled()) {
postOptRules.addAll(HepUtils.ScalarSubqueryJoinRules);
}
if (kylinConfig.isOptimizedSumCastDoubleRuleEnabled()) {
postOptRules.addAll(HepUtils.SumCastDoubleRules);
}
if (kylinConfig.isQueryFilterReductionEnabled()) {
postOptRules.addAll(HepUtils.FilterReductionRules);
}
postOptRules.add(OlapFilterJoinRule.FILTER_ON_JOIN);
// this rule should after sum-expression and count-distinct-expression
postOptRules.add(OlapProjectJoinTransposeRule.INSTANCE);
RelNode transformed = HepUtils.runRuleCollection(node, postOptRules, false);
if (transformed != node && allowAlternativeQueryPlan) {
return Lists.newArrayList(transformed, node);
} else {
return Lists.newArrayList(transformed);
}
}RBO 阶段执行优化的逻辑和 CBO 阶段类似,不同的是 RBO 只会按照固定添加的优化规则顺序匹配并依次执行,不会重复进入同样的优化规则(除非添加两次且都符合条件),同时这一阶段也不会计算 cost,这是两者最大的区别。
Spark
模型匹配后的逻辑则是在 Spark 这一层做的,中间省略了模型匹配的过程。
Details
到这步,就需要将 Calcite 的查询逻辑计划转换为 Spark 的查询逻辑计划,见 CalciteToSparkPlaner#visit。
按照查询计划从下往上依次进行转换
转换时跳过 OlapJoinRel/OlapNonEquiJoinRel 且不是 runtime join 的情况,runtime join 指匹配不上索引需要现算
CalciteToSparkPlaner#convertTableScan方法在转换 OlapTableScan 和 OlapJoinRel 时都会用到,也就是说对于 join 这种场景,在前面的逻辑成功匹配模型索引后,真正执行时直接扫描两张表已经 join 之后的数据地址即可,无需真正扫描两张表再 join 计算,这些信息在构建模型索引时和数据地址一并存储在模型索引的元数据信息中对于非 admin 用户,在转换完成返回 Spark DataSet 时会对数据做一些其他操作,比如数据脱敏
真正执行计算时会判断数据入口,这里会判断是否来自于 MDX 的计算,之前 Kylin 开源过一版和 MDX 的对接,见:QuickStartForMDX ,MDX 是一种类似 SQL 的查询语法,但其抽象程度比 SQL 更高,拥有类似 Hierarchy 这样的概念,用户多会通过 Excel 使用后台对接 MDX 进行查询,最早由微软开放出来而现在已经放弃了该项目,相对来说用的人很少,市面上资料比较少,门槛也高。之前 Kylin 商业版开发过 MDX on Spark 的项目,主要目的是使 MDX 能够拥有分布式计算的能力,我是该攻坚项目的核心研发之一,项目并未开源。在此基础上,有一种场景是客户使用 Excel 拖拉拽式查询,后台通过 MDX + Kylin -> Calcite/Spark 的方式匹配预计算结果返回,体验还是不错的。
查询返回有两种情况
- 异步查询:提交异步任务计算,结果保存在 HDFS,一般通过单独的接口调用,mock 虚拟结果直接返回
- 即时查询:基于文件大小估算分区数量,记录执行任务的相关信息,在通过大查询校验后(通过扫描行数以及相关配置参数来判断是否拒绝此查询),真正执行计算获得结果
查询引擎里的 Spark Driver 和 Kylin Server 在一个常驻进程里,内部将查询的 Spark 称为 Sparder 引擎以区分构建使用的 Spark 引擎
至此, 查询流程模型匹配前的 Calcite 处理和模型匹配后的 Spark 处理部分介绍完毕,后续再补充模型匹配处理流程。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!