How Apache Kylin Query Work(一)
本文最后更新于:2024年7月31日 下午
What is Query Engine
什么是查询引擎?有很多说法,普遍认知是一种可以对数据执行查询并生成答案的软件。
比如:今年公司每个月的平均销售额是多少?这个季度员工的平均薪资是多少?这些查询作用在用户构建的数据之上,执行并返回答案,最广泛的查询语言是结构化查询语言 SQL,下面是一条 SQL 查询
SELECT month, AVG(sales)
FROM product_sales
WHERE year = 2024
GROUP BY month;现在有很多流行的 SQL 查询引擎如 Hive、Impala、Presto、Spark SQL 等等,从本文开始将和大家一起讨论下 Apache Kylin 的查询是怎么工作的,这里摘录来自官网的描述:
Apache Kylin™是一个开源的、分布式的分析型数据仓库,提供Hadoop/Spark 之上的 SQL 查询接口及多维分析(OLAP)能力以支持超大规模数据,最初由 eBay 开发并贡献至开源社区。它能在亚秒内查询巨大的表。
Concepts
首先需要说明的是 Apache Kylin 使用 Apache Calcite 作为 SQL 入口,执行层使用的是 Apache Spark,文件存储格式使用的是 Apache Parquet,Kylin 的核心理念是预计算,也就是用空间换时间。
传统 RDBMS 使用行式存储,其着重点在于 ACID 事务,文件存储格式通常使用的是行式存储,无法很好地支撑高并发的大数据场景,本文讨论的 OLAP 领域着重点在于查询分析,使用列式存储作为文件存储格式更友好。
用户在从 Hive 加载数据源表,创建模型对应表与表之间的连接关系,同时定义好需要预计算的维度列、度量和可计算列,生成对应的聚合索引和明细索引。在执行构建索引的步骤之后,即可通过预计算生成的索引结果回答查询。
补充说明:Kylin 支持的数据模型为星型模型和雪花模型,不支持多张事实表的星座模型。
Type System
Schema
通常类型系统一般称为 Schema,为数据源或查询结果提供元数据,由不同的字段和数据类型组成,还包含一些另外的信息如:是否允许 null 值、字段的存储格式等。
Kylin 在继承 Calcite 抽象类 CalciteSchema 的基础上实现了自定义 Schema —— OlapSchema,同时会注入 Kylin 自己实现的 UDF 函数。
其中有两个比较重要的信息
- TableDescs:加载至 Kylin 的表元数据,通常以 json 文件的形式存储在分布式存储系统 HDFS 上
- ColumnDesc:来自于数据源的列元数据,包含列名、数据类型、可计算列等信息
- NDataModel:模型元数据,包含一个事实表与多个维表以及用户定义的需要预计算的维度列、度量、衍生维度列等信息
- 可计算列在 Kylin 中又称为 CC 列(即 Computed Column),如:
TEST_KYLIN_FACT.PRICE * TEST_KYLIN_FACT.ITEM_COUNT的结果可以直接定义为一种特殊的可计算列。- 衍生维度列:只要事实表对应外键被加入聚合索引并构建,且该维度表有 Snapshot,那么该列被称为衍生维度列,即便没有定义成预计算列也能通过索引进行回答。
Type
Kylin 在继承 Calcite 抽象类 RelDataTypeSystemImpl 的基础上实现了自定义数据类型 —— KylinRelDataTypeSystem。
主要针对一些计算如 SUM 算子和 Decimal 的乘除法等做了类型调整和适配,因为 Kylin 需要兼容 Calcite 和 Spark 两者的类型系统,同时还有查询优化时对数据类型的微调等。
Data Sources
数据源模块非常重要,如果没有可读取的数据源,查询引擎将毫无用处,通常情况每个查询引擎都会有一个用来与数据源交互的接口以支持多个数据源。
Kylin 中的数据源接口是 org.apache.kylin.source.ISource,子类实现已支持的有 CsvSource、JdbcSource、NSparkDataSource 和 NSparkKafkaSource。
可以参考 CsvSource 简单理解加载过程,其中使用最多的是 NSparkDataSource,即来自于 Hive 的数据源,用户在加载数据源时 Kylin 会将表类型保存在表的元数据中,在后面的加载中不需要用户关心使用哪种 DataSource,而是由 Kylin 的 DataSource 基于表的元数据信息自适应子类实现加载表,这也正是数据源模块接口抽象出来的作用。
Logical Plan
逻辑计划是数据查询的结构化表示形式,描述了从数据库或数据源检索数据所需的操作和转换,抽象出特定的实现细节,并专注于查询的逻辑,如 filter、sort 和 join 等操作。每个逻辑计划都可以有 0 个或多个逻辑计划作为输入,逻辑计划可以暴露其子计划,以便使用 visitor 模式遍历。
Kylin 引入 Calcite 作为模型匹配前的查询引擎,同时引入 Spark 作为模型匹配后的查询引擎,因此包含这两部分查询逻辑计划。
Calcite 主要在解析查询和优化阶段使用,而 Spark 则是真正的执行层,这两者查询逻辑计划需要相互转换,后面有时间再展开讲,这里仅作提及。
部分常量计算执行引擎是交由 Calcite 执行的,因为一些简单的计算时间远小于 Spark 框架调用执行的时间。
Printing Logical Plans
以人类可读的形式打印逻辑计划对调试非常重要,这里贴一下 Kylin 输出逻辑计划的方式。
- Calcite
RelNode root = xxx; RelOptUtil.toString(root); - Spark
Dataset<Row> sparkPlan = xxx; sparkPlan.queryExecution().logical()
Serialization
通过序列化查询计划可以将其转移到另一个进程,通常有两种方法,Kylin 因为直接使用了 Calcite 和 Spark 的缘故,无需关注查询逻辑计划的序列化部分,不过在元数据模块中使用到 Jackson 的序列化。
- 使用实现语言的默认机制对数据进行转化,如 Java 的 Jackson 库,Kotli 的 kotlinx.serialization 库,Rust 的 serde crate 等
- 使用与语言无关的序列化格式,然后编写代码在此格式和实现语言的格式之间进行转换,如 Avro、Thrift 和 Protocol Buffers 等
Logical Expressions
查询计划的一个基本概念是逻辑表达式,可以在运行时根据数据进行计算,如:Column Expressions、Literal Expressions、Binary Expressions、Comparison Expressions、Math Expressions、Aggregate Expressions 等,参考下表给出的例子。
| Expression | Examples |
|---|---|
| Literal Value | “hello”, 12.34 |
| Column Reference | user_id, first_name, last_name |
| Math Expression | salary * state_tax |
| Comparison Expression | x ≥ y |
| Boolean Expression | birthday = today() AND age ≥ 21 |
| Aggregate Expression | MIN(salary), MAX(salary), SUM(salary), AVG(salary), COUNT(*) |
| Scalar Function | CONCAT(first_name, “ “, last_name) |
| Aliased Expression | salary * 0.02 AS pay_increase |
Logical Plans
有了逻辑表达式,接下来就是对查询引擎支持的各种转换实现逻辑计划,如:Scan、Projection、Selection(Filter)、Aggregate 等。
- Scan:从可选 Projection 的 数据源中提取数据,Scan 是查询逻辑计划中唯一没有另一个逻辑计划作为输入的逻辑计划,它是查询树中的叶子节点。
- Projection:作用在输入的逻辑计划之上,如:
SELECT a、b、c FROM foo这里的 a、b、c 列即为 Projection。 - Selection(Filter):应用在输入的逻辑计划之上,筛选结果中包含的行,如:
SELECT * FROM foo WHERE a > 5,这里的 a > 5 即为 Selection,也称为 Filter。 - Aggregate:计算基础数据的聚合结果,最小值、最大值、平均值和总和等。如:
SELECT job,AVG(salary) FROM EMPLOYEE GROUP BY job,这里 AVG(salary) 就是聚合计算的算子。
DataFrames
已经有了查询逻辑计划为什么还需要 DataFrames 呢?参考下面的例子,每个逻辑表达式都很清晰,但是整块代码比较分散,无法统一起来
// create a plan to represent the data source
val csv = CsvDataSource("employee.csv")
// create a plan to represent the scan of the data source (FROM)
val scan = Scan("employee", csv, listOf())
// create a plan to represent the selection (WHERE)
val filterExpr = Eq(Column("state"), LiteralString("CO"))
val selection = Selection(scan, filterExpr)
// create a plan to represent the projection (SELECT)
val projectionList = listOf(Column("id"),
Column("first_name"),
Column("last_name"),
Column("state"),
Column("salary"))
val plan = Projection(selection, projectionList)
// print the plan
println(format(plan))
打印的逻辑计划如下
Projection: #id, #first_name, #last_name, #state, #salary
Filter: #state = 'CO'
Scan: employee; projection=None如果有 DataFrame 做一层抽象,那么就可以写出像下面这样的代码,非常简洁,参照 Spark 的 DataFrame 做类比。
val df = ctx.csv(employeeCsv)
.filter(col("state") eq lit("CO"))
.select(listOf(
col("id"),
col("first_name"),
col("last_name"),
col("salary"),
(col("salary") mult lit(0.1)) alias "bonus"))
.filter(col("bonus") gt lit(1000))Physical Plans
通常情况下查询会分为逻辑计划和物理计划,合在一起降低复杂性也是可以的,但出于其他考量会将两者分开。
逻辑计划主要负责关系的逻辑表达和优化,而物理计划则是在逻辑计划的基础上根据数据的实际分布情况进一步优化制定执行计划,确保查询效率最大化。
这里以 Column Expressions 来举例,在 Logical Plans 中,Column 表示对命名列的引用,这个“列”可以是由输入的逻辑计划生成的列,也可以表示数据源中的列,或者针对其他输入表达式计算的结果,而在 Physical Plans 中, Column 为了避免每次计算表达式时都要查找名称的成本,可能会改为按索引引用列,直接对应了数据实际存储的序号引用。
Query Planning
在定义了逻辑计划和物理计划之后,还需要有一个可以将逻辑计划转换为物理计划的查询计划器,某种程度上还可以通过配置自适应选择不同的转换方式执行查询。
同样以 Column Expressions 为例,逻辑表达式按名称引用列,但物理表达式使用列索引来提高性能,那么就需要一个从列名到列序的转换,并在无效时报错,简单列出一些代码方便理解。
fun createPhysicalExpr(expr: LogicalExpr,
input: LogicalPlan): PhysicalExpr = when (expr) {
is ColumnIndex -> ColumnExpression(expr.i)
is LiteralString -> LiteralStringExpression(expr.str)
is BinaryExpr -> {
val l = createPhysicalExpr(expr.left, input)
val r = createPhysicalExpr(expr.right, input)
...
}
...
}
is Column -> {
val i = input.schema().fields.indexOfFirst { it.name == expr.name }
if (i == -1) {
throw SQLException("No column named '${expr.name}'")
}
ColumnExpression(i)
Query Optimizers
Kylin 使用了 Calcite 中的 VolcanoPlanner 和 HepPlanner 来进行查询优化,分别对应 CBO 和 RBO,这里不展开细讲,仅列举业界一些常用的优化方式来说明。
Rule-Based-Optimizations
基于规则的优化,按照一系列规则遍历并优化逻辑计划,将其转换为同等的 SQL 执行计划的优化规则。
Projection Push-Down
投影下推:尽可能早地在读取数据时筛选出列,以减少内存中所需处理的数据量。
优化前
Projection: #id, #first_name, #last_name
Filter: #state = 'CO'
Scan: employee; projection=None优化后
Projection: #id, #first_name, #last_name
Filter: #state = 'CO'
Scan: employee; projection=[first_name, id, last_name, state]同样是查询 id、first_name、last_name 这三列,优化前是读取整张 employee 表再做过滤处理,优化后则是仅读取 employee 表中的 id、first_name、last_name 这三列数据,在大数据量量下两者可能存在指数级的差距,毕竟在很多 OLAP 场景中都使用的列式文件存储格式。
Predicate Push-Down
谓词下推:尽早在查询中过滤行,以避免冗余处理。
优化前
Projection: #dept_name, #first_name, #last_name
Filter: #state = 'CO'
Join: #employee.dept_id = #dept.id
Scan: employee; projection=[first_name, id, last_name, state]
Scan: dept; projection=[id, dept_name]优化后
Projection: #dept_name, #first_name, #last_name
Join: #employee.dept_id = #dept.id
Filter: #state = 'CO'
Scan: employee; projection=[first_name, id, last_name, state]
Scan: dept; projection=[id, dept_name]在先对 employee 表做了 state = ‘CO’ 的过滤条件处理后,再将 employee 表和 dept 表 join 起来毫无疑问是减少很多开销的。
Eliminate Common Subexpression
消除子表达式:重用子表达式,而不是重复执行多次计算。
优化前
Projection: sum(#price * #qty), sum(#price * #qty * #tax)
Scan: sales优化后
Projection: sum(#_price_mult_qty), sum(#_price_mult_qty * #tax)
Projection: #price * #qty as _price_mult_qty
Scan: salesCost-Based-Optimizations
基于成本的优化,使用底层数据的统计信息来确定执行查询所需的成本,然后通过寻找低成本的执行计划选择最佳执行计划的优化规则。
这些统计信息通常包括列的空值情况、非重复值情况、最大最小值等信息,比如某一列可以直接通过最大最小值统计信息直接过滤掉部分数据文件的真正读取(这些信息是通过读取数据文件的元数据信息得到的),那么可以考虑将该列的执行时间往前放。
Query Execution
SQL 查询执行流程
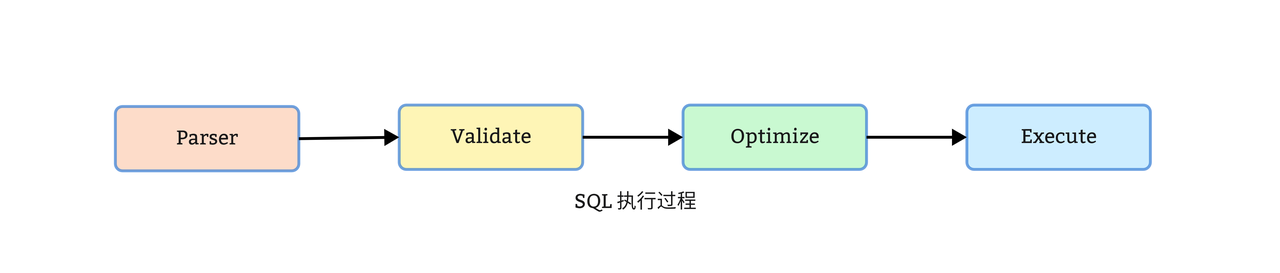
- 用户 SQL 进入查询引擎后,经由 Parser 转换为一棵抽象语法树 AST
- 接着通过绑定 Schema 元数据信息的校验阶段,此时这棵树会从 AST 转换为一个查询逻辑计划
- Optimize 阶段会应用 RBO/CBO 优化手段对逻辑计划进行优化
- 优化后的逻辑计划会再转换为物理计划分发到各个节点进行计算,并将结果汇报给主节点进行汇总计算得到最终查询结果
Kylin 查询执行流程
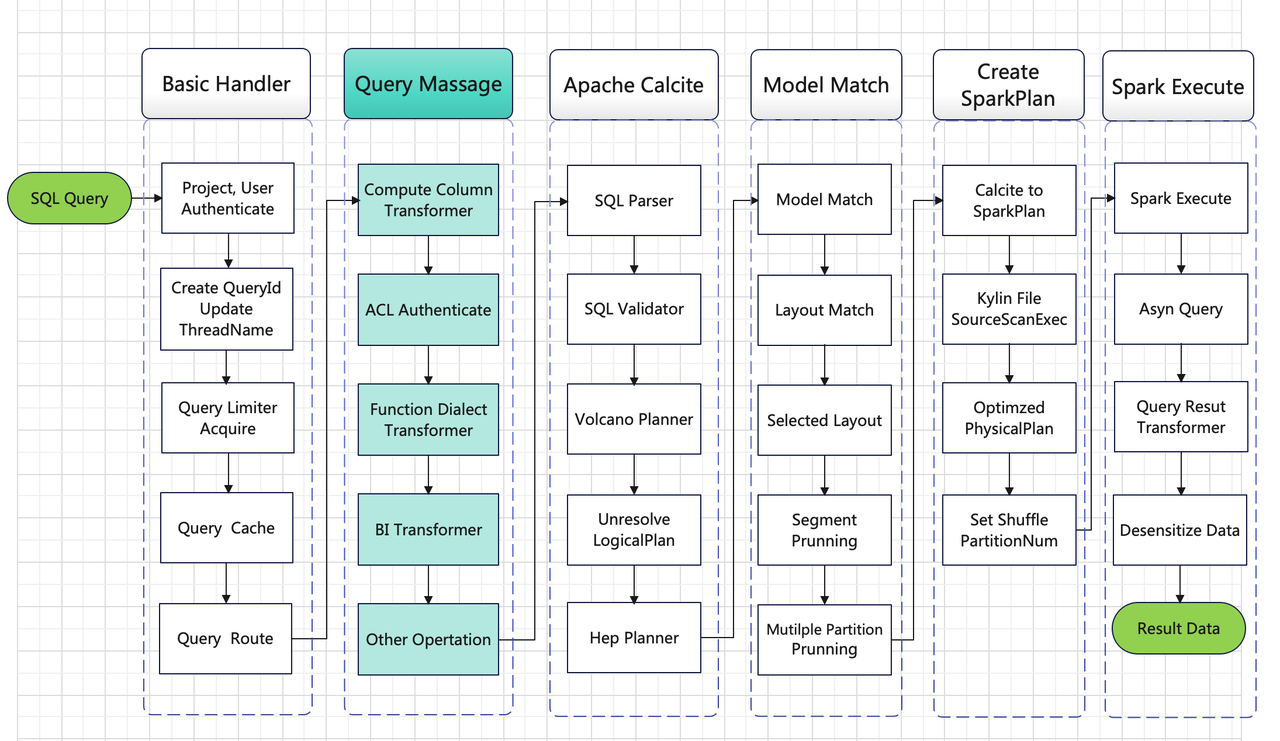
和传统查询引擎不同的点在于 Kylin 依赖于预计算,这也是其核心理念和功能:即用户在创建模型和索引之后执行构建任务先生成对应的索引结果,再进行查询的过程。这也是为什么在查询执行流程中间出现 Model Match 这一过程,可以先简单粗暴地把模型理解为物化视图,但两者区别挺大的,Kylin 的模型索引相较物化视图更灵活。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!