Apache Kylin 构建(一)
本文最后更新于:2025年1月23日 下午
FYI
- repo:https://github.com/apache/kylin
- branch:kylin5
- commitMessage:KYLIN-5846 upgrade spark version to 3.2.0-kylin-4.6.16.0
- commitID:3f9b9c83bedbce17be0dcac5af427c636353621a
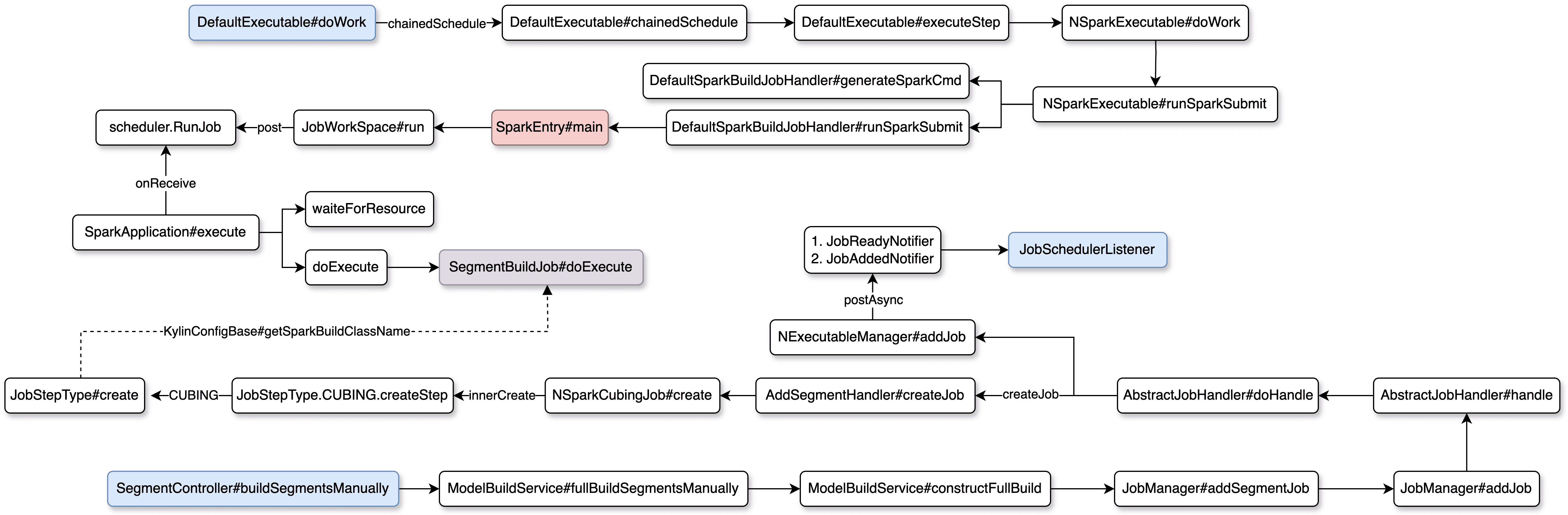
任务调度流程
当 Kylin 服务启动准备充分时,将初始化 EpochOrchestrator 并注册 ReloadMetadataListener,准备工作还包含其他定时任务,如打印堆栈信息、检查 HA 进程状态、移除过期任务等等。
初始化 EpochOrchestrator 的过程只会在非 query 节点进行(包括 all 节点和 job 节点,其中 all 节点既可构建也可查询),继而通过定时线程运行 EpochChecker 和 EpochRenewer,间隔时间可配置默认为 30s。
- EpochRenewer 负责选出 Epoch Owner 即元数据更新主节点,Kylin 支持 HA 功能,从节点只有读取权限,这里不向下深挖元数据相关逻辑。
- EpochChecker 会按照 project 依次更新 epoch,接着发出异步事件 ProjectControlledNotifier,当
EpochChangedListener#onProjectControlled监听到通知后在 project 层面通过NDefaultScheduler#init创建定时调度线程池,用于调度执行 JobCheckRunner 和 FetcherRunner。- JobCheckRunner
- 两个作用:一是检测到超时任务时将状态标记为失败并丢弃,二是当任务运行超过容量限制时停止任务。
- FetcherRunner
- 主要作用是调度任务,同时也会记录不同状态的任务数量,当任务执行完成时还会执行一些清理操作。
- JobCheckRunner
在 kylin5 分支中调度流程开始和结束时以及子任务调度执行起始都会有相应日志输出,不同日志会基于分类归类到不同的日志文件,如 kylin.schedule.log、kylin.query.log、kylin.build.log 和 kylin.metadata.log 等等,可参考类 KylinLogTool 查看更多日志类型。此外 Kylin 支持通过诊断包的形式定位排查问题,同时还有火焰图功能用于分析性能问题。(ps. 这些功能是我做的,不用担心我乱说,后面可能会另开单章讲火焰图功能,属实是性能分析利器)
当调度至 AbstractExecutable#execute 意味着进入到下一个任务创建阶段,在执行遇到异常时会进行重试,重试会默认等待 30s 以防止同一时刻任务提交过多。该方法有前置方法 onExecuteStart 和后置方法 onExecuteFinished,前置任务是为了更新任务状态,而后置任务除了改变任务状态外还支持以邮件方式通知使用者任务执行状态(商业版功能)。以调度至创建任务阶段为例,下图为任务调度流程

任务创建流程
Kylin 使用的是 SpringBoot 作为内部服务框架,采用的也是类似 MVC 架构的方式接收用户请求,这里以全量构建 Segment 为例进行说明。当用户在 UI 界面上点击全量构建 Segment 时,会按照图序逐步调用至 AbstractJobHandler#doHandle ,该方法中有两块重要逻辑
AbstractJobHandler#createJob(举例情况为AddSegmentHandler#createJob)NExecutableManager#addJob
createJob 用于准备构建 cube 时需要的上下文参数,包含 3 个子步骤
- JobStepType.RESOURCE_DETECT
- JobStepType.CUBING
- JobStepType.UPDATE_METADATA
在 JobStepType.CUBING 这一步,会通过指定 className 的方式给后续执行构建 Segment 的 Spark Application 设置主类,该参数通过 KylinConfigBase#getSparkBuildClassName 进行配置,默认是 org.apache.kylin.engine.spark.job.SegmentBuildJob 。
而 addJob 会在任务准备完成时发出 2 个事件
JobReadyNotifier
当 JobSchedulerListener 监听到 JobReadyNotifier 事件后会直接调用 FetcherRunner 调度任务。
JobAddedNotifier
当 JobSchedulerListener 监听到 JobAddedNotifier 事件后会记录一些任务的指标 metric 信息,输出到日志或者监控系统中。
接上面任务调度流程往下讲,AbstractExecutable#execute 调用的 doWork 方法默认实现是 DefaultExecutable 类,调用模式为 CHAIN 即串联执行(还有一种是 DAG 模式,该模式为商业版功能,主要是支持分层存储功能对接 ClickHouse 的索引)。executeStep 方法会依据上下文存储的步骤信息依次执行。NSparkExecutable#runSparkSubmit 需要关注两部分
generateSparkCmd
- generateSparkCmd 为运行 Spark Application 做了很多准备,包括:设置 HADOOP_CONF_DIR,指定主类为 SparkEntry,准备 sparkJars、sparkFiles 和 sparkConf,准备一会任务运行时的 jar 主类(如前文举例的
org.apache.kylin.engine.spark.job.SegmentBuildJob)等等。
- generateSparkCmd 为运行 Spark Application 做了很多准备,包括:设置 HADOOP_CONF_DIR,指定主类为 SparkEntry,准备 sparkJars、sparkFiles 和 sparkConf,准备一会任务运行时的 jar 主类(如前文举例的
runSparkSubmit
- ps. Kylin 异步查询也复用了该逻辑执行查询任务。
其实在 runSparkSubmit 中执行提交任务时会有个区分,即在本地运行提交 Spark submit 还是通过远程在 ClickHouse 上执行相关任务(商业版功能),这里只对本地提交的方式加以说明。提交任务后,省略 Spark RPC 通信逻辑,就进入到 SegmentBuildJob#main 方法,真正意义上完成了任务的创建流程,下图为任务创建流程
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!