Spark 调度系统
本文最后更新于:2025年1月20日 下午
概述
Spark 调度系统用于将用户提交的任务调度到集群中的不同节点执行,资源调度分为两层,第一层是 Cluster Manager(YARN 模式下为 ResourceManager,Mesos 模式下为 Mesos Master,Standalone 模式为 Master),将资源分配给 Application;第二层是 Application 进一步将资源分配给各个 Task,也就是 TaskScheduler(TaskSchedulerImpl)中的资源调度。
用户向 Spark 提交一个任务,Spark 看作是一个作业(Job),首先对 Job 进行一系列 RDD 转换,并通过 RDD 之间的依赖关系构建有向无环图(DAG)。然后根据 RDD 依赖的不同将 RDD 划分到不同的阶段(Stage),每个阶段按照分区(Partition)的数量创建多个任务(Task),最后将这些任务提交到集群的各个节点上运行。
调度系统主要由 DAGScheduler 和 TaskScheduler 构成。
工作流程图
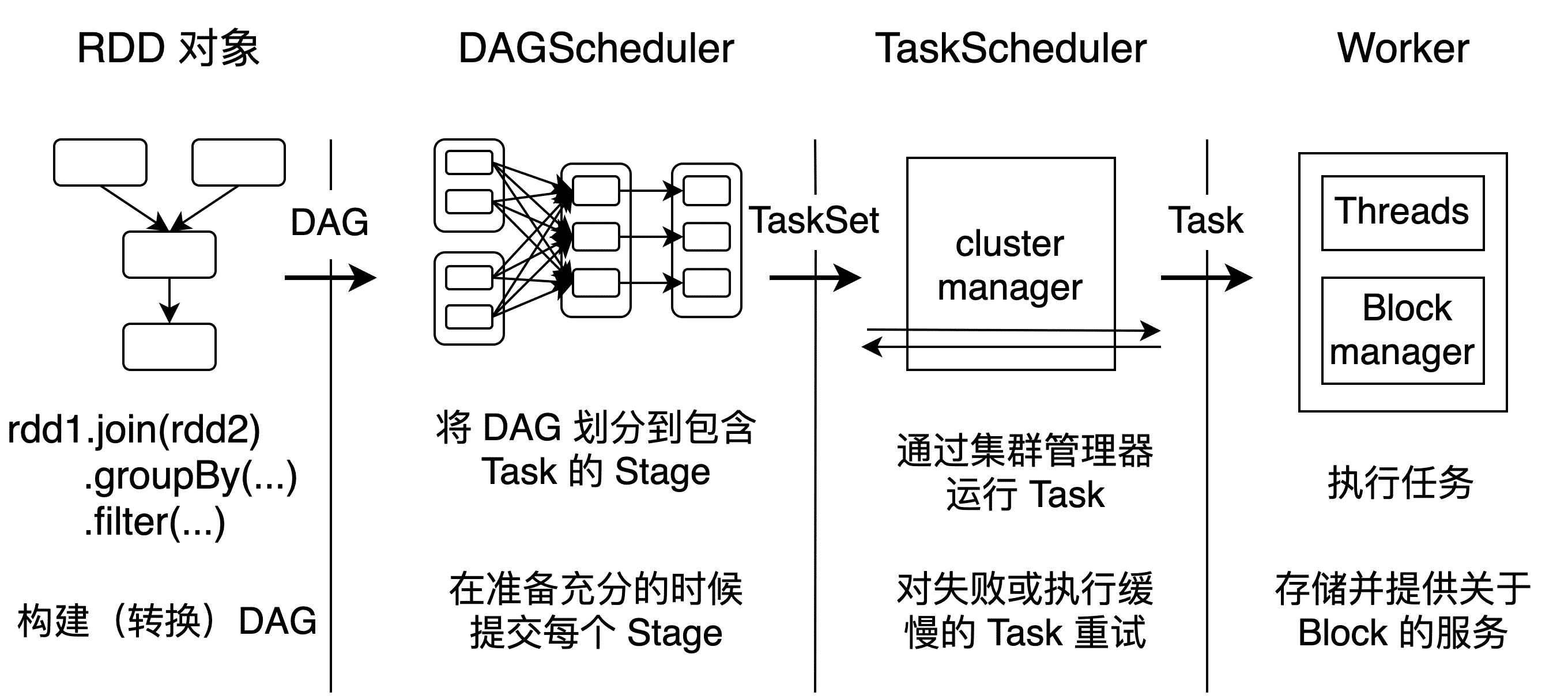
DAGScheduler
所有的组件都通过向 DAGScheduler 投递 DAGSchedulerEvent 来使用 DAGScheduler,其内部的 DAGSchedulerEventProcessLoop 将处理这些 DAGSchedulerEvent。
JobListener在向 DAGScheduler 提交作业之后,用于监听作业完成或失败事件的接口。每当任务成功以及整个作业失败时,侦听器都会收到通知。
JobWaiter等待DAGScheduler作业完成的对象。任务完成后,它将结果传递给给定的处理函数。
ActiveJob用来表示已经激活的 Job,即被 DAGScheduler 接收处理的 Job。
DAGSchedulerEventProcessLoopDAGSchedulerEventProcessLoop 是 DAGScheduler 内部的事件循环处理器,用于处理 DAGSchedulerEvent 类型的事件。
TaskScheduler
TaskScheduler 定义了对任务进行调度的接口规范,允许向 Spark 调度系统插入不同的 TaskScheduler 实现,但目前只有 TaskSchedulerImpl 这一个具体实现。只为单个 Driver 调度任务,功能包括接收 DAGScheduler 给每个 Stage 创建的 Task 集合,按照调度算法将资源分配给 Task,将 Task 交给 Spark 集群不同节点上的 Executor 运行,在 Task 执行失败时重试,通过推断执行减轻落后 Task 对整体作业进度的影响。
源码分析
源码流程图
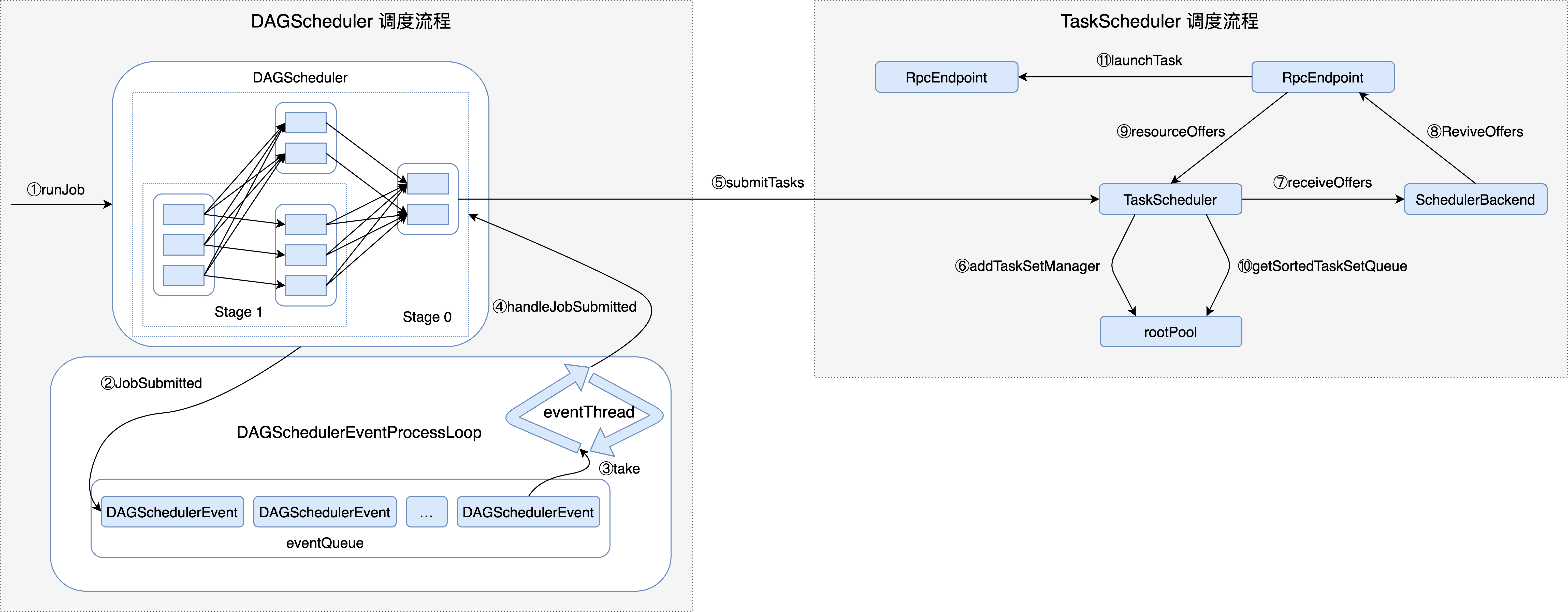
源码
我们从 SparkContext 开始,SparkContext 提供了多个重载的 runJob 方法,但这些方法最终都调用此方法。
def runJob[T, U: ClassTag](
rdd: RDD[T],
func: (TaskContext, Iterator[T]) => U,
partitions: Seq[Int],
resultHandler: (Int, U) => Unit): Unit = {
if (stopped.get()) {
throw new IllegalStateException("SparkContext has been shutdown")
}
val callSite = getCallSite
val cleanedFunc = clean(func)
logInfo("Starting job: " + callSite.shortForm)
if (conf.getBoolean("spark.logLineage", false)) {
logInfo("RDD's recursive dependencies:\n" + rdd.toDebugString)
}
// 将 DAG 及 RDD 提交给 DAGScheduler 进行调度
dagScheduler.runJob(rdd, cleanedFunc, partitions, callSite, resultHandler, localProperties.get)
progressBar.foreach(_.finishAll())
// 保存检查点
rdd.doCheckpoint()
}生成 Job 的运行时间 start 并调用 submitJob 方法提交 Job。由于执行 Job 的过程是异步的,因此 submitJob 将立即返回 JobWaiter 对象。使用 JobWaiter 等待 Job 处理完毕。
def runJob[T, U](
rdd: RDD[T],
func: (TaskContext, Iterator[T]) => U,
partitions: Seq[Int],
callSite: CallSite,
resultHandler: (Int, U) => Unit,
properties: Properties): Unit = {
val start = System.nanoTime
// 提交 Job
val waiter = submitJob(rdd, func, partitions, callSite, resultHandler, properties)
// JobWaiter 等待 Job 处理完毕
ThreadUtils.awaitReady(waiter.completionFuture, Duration.Inf)
waiter.completionFuture.value.get match {
// JobWaiter 监听到 Job 的处理结果,进行进一步处理
case scala.util.Success(_) =>
// 如果 Job 执行成功,根据处理结果打印相应的日志
logInfo("Job %d finished: %s, took %f s".format
(waiter.jobId, callSite.shortForm, (System.nanoTime - start) / 1e9))
case scala.util.Failure(exception) =>
// 如果 Job 执行失败,除打印日志外,还将抛出 Job 失败的异常信息
logInfo("Job %d failed: %s, took %f s".format
(waiter.jobId, callSite.shortForm, (System.nanoTime - start) / 1e9))
val callerStackTrace = Thread.currentThread().getStackTrace.tail
exception.setStackTrace(exception.getStackTrace ++ callerStackTrace)
throw exception
}
}在检查 Job 分区数量符合条件后,会向 DAGSchedulerEventProcessLoop 发送 JobSubmitted 事件,同时会将事件放入 eventQueue(LinkedBlockingDeque)中。
def submitJob[T, U](
rdd: RDD[T],
func: (TaskContext, Iterator[T]) => U,
partitions: Seq[Int],
callSite: CallSite,
resultHandler: (Int, U) => Unit,
properties: Properties): JobWaiter[U] = {
// 获取当前 Job 的最大分区数 maxPartitions
val maxPartitions = rdd.partitions.length
partitions.find(p => p >= maxPartitions || p < 0).foreach { p =>
throw new IllegalArgumentException(
"Attempting to access a non-existent partition: " + p + ". " +
"Total number of partitions: " + maxPartitions)
}
// 生成下一个 Job 的 jobId
val jobId = nextJobId.getAndIncrement()
// 如果 Job 分区数为 0,创建一个 totalTasks 属性为 0 的 JobWaiter 并返回
if (partitions.size == 0) {
return new JobWaiter[U](this, jobId, 0, resultHandler)
}
assert(partitions.size > 0)
val func2 = func.asInstanceOf[(TaskContext, Iterator[_]) => _]
// 创建等待 Job 完成的 JobWaiter
val waiter = new JobWaiter(this, jobId, partitions.size, resultHandler)
// 向 DAGSchedulerEventProcessLoop 发送 JobSubmitted 事件
eventProcessLoop.post(JobSubmitted(
jobId, rdd, func2, partitions.toArray, callSite, waiter,
SerializationUtils.clone(properties)))
waiter
}而 DAGSchedulerEventProcessLoop 会轮询 eventQueue 中的事件(event),再通过 onReceive方法接收事件,最终到达 DAGScheduler 中的 doOnReceive 方法匹配对应的事件进行处理。
private def doOnReceive(event: DAGSchedulerEvent): Unit = event match {
case JobSubmitted(jobId, rdd, func, partitions, callSite, listener, properties) =>
dagScheduler.handleJobSubmitted(jobId, rdd, func, partitions, callSite, listener, properties)
// 省略其他事件
}创建 ResultStage 并处理这个过程中可能发生的异常(如依赖的 HDFS 文件被删除),创建 ActiveJob 并处理,向 LiveListenerBus 投递 SparkListenerJobStart 事件(引发监听器执行相应操作),其中最重要的是调用 submitStage 方法提交 ResultStage。
private[scheduler] def handleJobSubmitted(jobId: Int,
finalRDD: RDD[_],
func: (TaskContext, Iterator[_]) => _,
partitions: Array[Int],
callSite: CallSite,
listener: JobListener,
properties: Properties) {
var finalStage: ResultStage = null
try {
// 创建 ResultStage
finalStage = createResultStage(finalRDD, func, partitions, jobId, callSite)
} catch {
// 省略异常捕获代码
return
}
barrierJobIdToNumTasksCheckFailures.remove(jobId)
// 创建 ActiveJob
val job = new ActiveJob(jobId, finalStage, callSite, listener, properties)
clearCacheLocs()
logInfo("Got job %s (%s) with %d output partitions".format(
job.jobId, callSite.shortForm, partitions.length))
logInfo("Final stage: " + finalStage + " (" + finalStage.name + ")")
logInfo("Parents of final stage: " + finalStage.parents)
logInfo("Missing parents: " + getMissingParentStages(finalStage))
// 生产 Job 的提交时间
val jobSubmissionTime = clock.getTimeMillis()
jobIdToActiveJob(jobId) = job
activeJobs += job
finalStage.setActiveJob(job)
val stageIds = jobIdToStageIds(jobId).toArray
val stageInfos = stageIds.flatMap(id => stageIdToStage.get(id).map(_.latestInfo))
listenerBus.post(
SparkListenerJobStart(job.jobId, jobSubmissionTime, stageInfos, properties))
// 提交 ResultStage
submitStage(finalStage)
}获取当前 Stage 的所有 ActiveJob 身份标识,如果有身份标识,但 Stage 未提交,则查看父 Stage。父 Stage 也未提交,那么调用 submitStage 逐个提交所有未提交的 Stage,父 Stage 已经提交,那么调用 submitMissingTasks 提交当前 Stage 未提交的 Task。如果没有身份标识,直接终止依赖于当前 Stage 的所有 Job。
private def submitStage(stage: Stage) {
// 获取当前 Stage 对应的 Job 的 ID
val jobId = activeJobForStage(stage)
if (jobId.isDefined) {
logDebug(s"submitStage($stage (name=${stage.name};" +
s"jobs=${stage.jobIds.toSeq.sorted.mkString(",")}))")
if (!waitingStages(stage) && !runningStages(stage) && !failedStages(stage)) {
// 当前 Stage 未提交
val missing = getMissingParentStages(stage).sortBy(_.id)
logDebug("missing: " + missing)
// 不存在未提交的父 Stage,那么提交当前 Stage 所有未提交的 Task
if (missing.isEmpty) {
logInfo("Submitting " + stage + " (" + stage.rdd + "), which has no missing parents")
submitMissingTasks(stage, jobId.get)
} else {
// 存在未提交的父 Stage,那么逐个提交它们
for (parent <- missing) {
submitStage(parent)
}
waitingStages += stage
}
}
} else { // 终止依赖于当前 Stage 的所有 Job
abortStage(stage, "No active job for stage " + stage.id, None)
}
}此方法在 Stage 没有不可用的父 Stage 时,提交当前 Stage 还未提交的任务。
调用 Stage 的 findMissingPartitions 方法,找出当前 Stage 的所有分区中还没有完成计算的分区的索引
获取 ActiveJob 的 properties。properties 包含了当前 Job 的调度、group、描述等属性信息
将当前 Stage 加入 runningStages 集合中,即当前 Stage 已经处于运行状态
调用 OutputCommitCoordinator 的 stageStart 方法,启动对当前 Stage 的输出提交到 HDFS 的协调
调用 DAGScheduler 的 getPreferredLocs 方法,获取 partitionsToCompute 中的每一个分区的偏好位置。如果发生异常,则调用 Stage 的 makeNewStageAttempt 方法开始一次新的 Stage 执行尝试,然后向 listenerBus 投递 SparkListenerStageSubmitted 事件
调用 Stage 的 makeNewStageAttempt 方法开始 Stage 的执行尝试,并向 listenerBus 投递 SparkListenerStageSubmitted 事件
如果当前 Stage 是 ShuffleMapStage,那么对 Stage 的 rdd 和 ShuffleDependency 进行序列化;如果当前 Stage 是 ResultStage,那么对 Stage 的 rdd 和对 RDD 的分区进行计算的函数 func 进行序列化
调用 SparkContext 的 broadcast 方法广播上一步生成的序列化对象
如果当前 Stage 是 ShuffleMapStage,则为 ShuffleMapStage 的每一个分区创建一个 ShuffleMapTask。如果当前 Stage 是 ResultStage,则为 ResultStage 的每一个分区创建一个 ResultTask。
如果第 9 步中创建了至少一个 Task,那么为这批 Task 创建 TaskSet(即任务集合),并调用 TaskScheduler 的 submitTasks 方法提交此批 Task
如果第 10 步没有创建任何 Task,这意味着当前 Stage 没有 Task 任务需要提交执行,因此调用 DAGScheduler 的 markStageAsFinished 方法,将当前 Stage 标记为完成。然后调用 submitWaitingChildStages 方法,提交当前 Stage 的子 Stage。
private def submitMissingTasks(stage: Stage, jobId: Int) {
logDebug("submitMissingTasks(" + stage + ")")
// 找出当前 Stage 的所有分区中还没有完成计算的分区的索引
val partitionsToCompute: Seq[Int] = stage.findMissingPartitions()
// 获取 ActiveJob 的 properties。properties 包含了当前 Job 的调度、group、描述等属性信息
val properties = jobIdToActiveJob(jobId).properties
runningStages += stage
// 启动对当前 Stage 的输出提交到 HDFS 的协调
stage match {
case s: ShuffleMapStage =>
outputCommitCoordinator.stageStart(stage = s.id, maxPartitionId = s.numPartitions - 1)
case s: ResultStage =>
outputCommitCoordinator.stageStart(
stage = s.id, maxPartitionId = s.rdd.partitions.length - 1)
}
val taskIdToLocations: Map[Int, Seq[TaskLocation]] = try {
// 获取还没有完成计算的每一个分区的偏好位置
stage match {
case s: ShuffleMapStage =>
partitionsToCompute.map { id => (id, getPreferredLocs(stage.rdd, id))}.toMap
case s: ResultStage =>
partitionsToCompute.map { id =>
val p = s.partitions(id)
(id, getPreferredLocs(stage.rdd, p))
}.toMap
}
} catch {
// 如果发生任何异常,则调用 Stage 的 makeNewStageAttempt 方法开始一次新的 Stage 执行尝试
case NonFatal(e) =>
stage.makeNewStageAttempt(partitionsToCompute.size)
listenerBus.post(SparkListenerStageSubmitted(stage.latestInfo, properties))
abortStage(stage, s"Task creation failed: $e\n${Utils.exceptionString(e)}", Some(e))
runningStages -= stage
return
}
// 开始 Stage 的执行尝试
stage.makeNewStageAttempt(partitionsToCompute.size, taskIdToLocations.values.toSeq)
if (partitionsToCompute.nonEmpty) {
stage.latestInfo.submissionTime = Some(clock.getTimeMillis())
}
listenerBus.post(SparkListenerStageSubmitted(stage.latestInfo, properties))
var taskBinary: Broadcast[Array[Byte]] = null
var partitions: Array[Partition] = null
try {
// 对于 ShuffleMapTask,进行序列化和广播 (rdd, shuffleDep).
// 对于 ResultTask,进行序列化和广播 (rdd, func).
var taskBinaryBytes: Array[Byte] = null
// taskBinaryBytes 和分区都受检查点状态影响,如果另一个并发 Job 正在为此 RDD 设置检查点,则需要进行同步
RDDCheckpointData.synchronized {
taskBinaryBytes = stage match {
case stage: ShuffleMapStage =>
JavaUtils.bufferToArray(
closureSerializer.serialize((stage.rdd, stage.shuffleDep): AnyRef))
case stage: ResultStage =>
JavaUtils.bufferToArray(closureSerializer.serialize((stage.rdd, stage.func): AnyRef))
}
partitions = stage.rdd.partitions
}
// 广播任务的序列化对象
taskBinary = sc.broadcast(taskBinaryBytes)
} catch {
// 如果序列化失败,终止该 Stage
case e: NotSerializableException =>
abortStage(stage, "Task not serializable: " + e.toString, Some(e))
runningStages -= stage
// 终止异常
return
case e: Throwable =>
abortStage(stage, s"Task serialization failed: $e\n${Utils.exceptionString(e)}", Some(e))
runningStages -= stage
// 终止异常
return
}
val tasks: Seq[Task[_]] = try {
val serializedTaskMetrics = closureSerializer.serialize(stage.latestInfo.taskMetrics).array()
stage match {
// 为 ShuffleMapStage 的每一个分区创建一个 ShuffleMapTask
case stage: ShuffleMapStage =>
stage.pendingPartitions.clear()
partitionsToCompute.map { id =>
val locs = taskIdToLocations(id)
val part = partitions(id)
stage.pendingPartitions += id
new ShuffleMapTask(stage.id, stage.latestInfo.attemptNumber,
taskBinary, part, locs, properties, serializedTaskMetrics, Option(jobId),
Option(sc.applicationId), sc.applicationAttemptId, stage.rdd.isBarrier())
}
// 为 ResultStage 的每一个分区创建一个 ResultTask
case stage: ResultStage =>
partitionsToCompute.map { id =>
val p: Int = stage.partitions(id)
val part = partitions(p)
val locs = taskIdToLocations(id)
new ResultTask(stage.id, stage.latestInfo.attemptNumber,
taskBinary, part, locs, id, properties, serializedTaskMetrics,
Option(jobId), Option(sc.applicationId), sc.applicationAttemptId,
stage.rdd.isBarrier())
}
}
} catch {
case NonFatal(e) =>
abortStage(stage, s"Task creation failed: $e\n${Utils.exceptionString(e)}", Some(e))
runningStages -= stage
return
}
// 调用 TaskScheduler 的 submitTasks 方法提交此批 Task
if (tasks.size > 0) {
logInfo(s"Submitting ${tasks.size} missing tasks from $stage (${stage.rdd}) (first 15 " +
s"tasks are for partitions ${tasks.take(15).map(_.partitionId)})")
taskScheduler.submitTasks(new TaskSet(
tasks.toArray, stage.id, stage.latestInfo.attemptNumber, jobId, properties))
} else {
// 没有创建任何 Task,将当前 Stage 标记为完成
markStageAsFinished(stage, None)
stage match {
case stage: ShuffleMapStage =>
logDebug(s"Stage ${stage} is actually done; " +
s"(available: ${stage.isAvailable}," +
s"available outputs: ${stage.numAvailableOutputs}," +
s"partitions: ${stage.numPartitions})")
markMapStageJobsAsFinished(stage)
case stage : ResultStage =>
logDebug(s"Stage ${stage} is actually done; (partitions: ${stage.numPartitions})")
}
submitWaitingChildStages(stage)
}
}DAGScheduler 将 Stage 中各个分区的 Task 封装为 TaskSet 后,会将 TaskSet 交给 TaskSchedulerImpl 处理,此方法是这一过程的入口。
获取 TaskSet 中的所有 Task。
调用 createTaskSetManager 方法创建 TaskSetManager
在 taskSetsByStageIdAndAttempt 中设置 TaskSet 关联的 Stage、Stage 尝试及刚创建的 TaskSetManager 之间的三级映射关系。
对当前 TaskSet 进行冲突检测,即 taskSetsByStageIdAndAttempt 中不应该存在同属于当前 Stage,但是 TaskSet 却不相同的情况。
调用调度池构建器的 addTaskSetManager 方法,将刚创建的 TaskSetManager 添加到调度池构建器的调度池中。
如果当前应用程序不是 Local 模式并且 TaskSchedulerImpl 还没有接收到 Task,那么设置一个定时器按照 STARVATION_TIMEOUT_MS 指定的时间间隔检查 TaskScheduleImpl 的饥饿状况,当 TaskScheduleImpl 已经运行 Task 后,取消此定时器
将 hasReceivedTask 设置为 tue,以表示 TaskSchedulerImpl 已经接收到 Task
调用 SchedulerBackend 的 reviveOffers 方法给 Task 分配资源并运行 Task
local 模式(其他模式也类似)
在提交的最后会调用 LocalSchedulerBackend 的 reviveOffers 方法
LocalSchedulerBackend 的 reviveOffers 方法只是向 LocalEndpoint 发送 ReviveOffers 消息
LocalEndpoint 收到 ReviveOffers 消息后,调用 TaskSchedulerImpl 的 resourceOffers 方法申请资源,TaskSchedulerImpl 将根据任务申请的 CPU 核数、内存、本地化等条件为其分配资源
override def submitTasks(taskSet: TaskSet) {
// 获取 TaskSet 中的所有 Task
val tasks = taskSet.tasks
logInfo("Adding task set " + taskSet.id + " with " + tasks.length + " tasks")
this.synchronized {
val manager = createTaskSetManager(taskSet, maxTaskFailures)
val stage = taskSet.stageId
val stageTaskSets =
taskSetsByStageIdAndAttempt.getOrElseUpdate(stage, new HashMap[Int, TaskSetManager])
// 将所有现有 TaskSetManager 标记为僵尸(当 TaskSetManager 所管理的 TaskSet 中所有 Task 都执行成功了,不再有更多的 Task 尝试被启动时,就处于“僵尸”状态)
stageTaskSets.foreach { case (_, ts) =>
ts.isZombie = true
}
stageTaskSets(taskSet.stageAttemptId) = manager
schedulableBuilder.addTaskSetManager(manager, manager.taskSet.properties)
// 设置检查 TaskSchedulerImpl 的饥饿状况的定时器
if (!isLocal && !hasReceivedTask) {
starvationTimer.scheduleAtFixedRate(new TimerTask() {
override def run() {
if (!hasLaunchedTask) {
logWarning("Initial job has not accepted any resources; " +
"check your cluster UI to ensure that workers are registered " +
"and have sufficient resources")
} else {
this.cancel()
}
}
}, STARVATION_TIMEOUT_MS, STARVATION_TIMEOUT_MS)
}
// 表示 TaskSchedulerImpl 已经接收到 Task
hasReceivedTask = true
}
// 给 Task 分配资源并运行 Task
backend.reviveOffers()
}上述代码中会向 SchedulableBuilder 添加 TaskSetManager,这个 SchedulableBuilder 定义的是调度池构建器的行为规范,针对 FIFO 和 FAIR 两种调度算法,默认调用实现 FIFOSchedulableBuilder。然后向根调度池中添加 TaskSetManager。
override def addTaskSetManager(manager: Schedulable, properties: Properties) {
rootPool.addSchedulable(manager)
}将 Schedulable 添加到 schedulableQueue 和 schedulableNameToSchedulable 中,并将 Schedulable 的父亲设置为当前 Pool。
override def addSchedulable(schedulable: Schedulable) {
require(schedulable != null)
schedulableQueue.add(schedulable)
schedulableNameToSchedulable.put(schedulable.name, schedulable)
schedulable.parent = this
}继续上文,通过 SchedulerBackend 给调度池中的所有 Task 分配资源。在 CoarseGrainedSchedulerBackend 中通过 driverEndpoint 发送 ReviveOffers 消息,在接收到消息后,继续进行处理。
private def makeOffers() {
// 确保在有 Task 运行的时候没有杀死 Executor
val taskDescs = withLock {
// 过滤掉被杀的 Executor
val activeExecutors = executorDataMap.filterKeys(executorIsAlive)
val workOffers = activeExecutors.map {
case (id, executorData) =>
new WorkerOffer(id, executorData.executorHost, executorData.freeCores,
Some(executorData.executorAddress.hostPort))
}.toIndexedSeq
// 接收资源消息
scheduler.resourceOffers(workOffers)
}
if (!taskDescs.isEmpty) {
// 启动 Task
launchTasks(taskDescs)
}
}给 Task 分配资源:
遍历 WorkerOffer 序列,对每一个 WorkerOffer 执行以下操作:
更新 Host 与 Executor 的各种映射关系。
调用 TaskSchedulerImpl 的 executorAdded 方法(此方法实际仅仅调用了 DagScheduler 的 executorAdded 方法)向 DagScheduler 的 DagSchedulerEventProcessLoop 投递 ExecutorAdded 事件。
标记添加了新的 Executor(即将 newExecAvail 设置为 true)
更新 Host 与机架之间的关系
对所有 WorkerOffer 随机洗牌,避免将任务总是分配给同样一组 Worker
根据每个 WorkerOffer 的可用的 CPU 核数创建同等尺寸的任务描述(TaskDescription)数组
将每个 WorkerOffer 的可用的 CPU 核数统计到可用 CPU (availableCpus)数组中
调用 rootPool 的 getSortedTaskSetQueue 方法,对 rootPool 中的所有 TaskSetManager 按照调度算法排序
如果 newExecAvail 为 true,那么调用每个 TaskSetManager 的 executorAdded 方法。此 executorAdded 方法实际调用了 computeValidLocalityLevels 方法重新计算 TaskSet 的本地性
遍历 TaskSetManager,按照最大本地性的原则(即从高本地性级别到低本地性级别调用 resourceOfferSingleTaskSet,给单个 TaskSet 中的 Task 提供资源。如果在任何 TaskSet 所允许的本地性级别下,TaskSet 中没有任何一个任务获得了资源,那么将调用 TaskSetManager 的 abortSinceCompletelyBlacklisted 方法,放弃在黑名单中的 Task
返回生成的 TaskDescription 列表,即已经获得了资源的任务列表
def resourceOffers(offers: IndexedSeq[WorkerOffer]): Seq[Seq[TaskDescription]] = synchronized {
// 将每个 slave 标记为活动的,记录其主机名,并追踪是否添加了新的 Executor
var newExecAvail = false
for (o <- offers) {
if (!hostToExecutors.contains(o.host)) {
hostToExecutors(o.host) = new HashSet[String]()
}
// 更新 Host 与 Executor 的各种映射关系
if (!executorIdToRunningTaskIds.contains(o.executorId)) {
hostToExecutors(o.host) += o.executorId
executorAdded(o.executorId, o.host)
executorIdToHost(o.executorId) = o.host
executorIdToRunningTaskIds(o.executorId) = HashSet[Long]()
// 标记添加了新的 Executor
newExecAvail = true
}
// 更新 Host 与机架之间的关系
for (rack <- getRackForHost(o.host)) {
hostsByRack.getOrElseUpdate(rack, new HashSet[String]()) += o.host
}
}
// 提供资源之前,从黑名单中删除过期节点,在这里操作是为了避免使用单独的线程增加开销,也因为只有在提供资源时才需要更新黑名单
blacklistTrackerOpt.foreach(_.applyBlacklistTimeout())
val filteredOffers = blacklistTrackerOpt.map { blacklistTracker =>
offers.filter { offer =>
!blacklistTracker.isNodeBlacklisted(offer.host) &&
!blacklistTracker.isExecutorBlacklisted(offer.executorId)
}
}.getOrElse(offers)
// 随机 shuffle,避免将任务总是分配给同样一组 Worker
val shuffledOffers = shuffleOffers(filteredOffers)
// 建立分配给每个 Worker 的任务列表
val tasks = shuffledOffers.map(o => new ArrayBuffer[TaskDescription](o.cores / CPUS_PER_TASK))
// 统计每个 Worker 的可用 CPU 核数
val availableCpus = shuffledOffers.map(o => o.cores).toArray
// 所有 TaskSetManager 按照调度算法排序
val sortedTaskSets = rootPool.getSortedTaskSetQueue
for (taskSet <- sortedTaskSets) {
logDebug("parentName: %s, name: %s, runningTasks: %s".format(
taskSet.parent.name, taskSet.name, taskSet.runningTasks))
if (newExecAvail) {
// 重新计算 TaskSet 的本地性
taskSet.executorAdded()
}
}
// 按照调度算法顺序获取 TaskSet,然后按照数据的本地性级别升序提供给每个节点,以便在所有节点上启动本地任务。所有的本地性级别顺序: PROCESS_LOCAL, NODE_LOCAL, NO_PREF, RACK_LOCAL, ANY
for (taskSet <- sortedTaskSets) {
val availableSlots = availableCpus.map(c => c / CPUS_PER_TASK).sum
// 如果可获得的资源数少于挂起的任务数,那么跳过有障碍的 TaskSet
if (taskSet.isBarrier && availableSlots < taskSet.numTasks) {
logInfo(s"Skip current round of resource offers for barrier stage ${taskSet.stageId} " +
s"because the barrier taskSet requires ${taskSet.numTasks} slots, while the total " +
s"number of available slots is $availableSlots.")
} else {
var launchedAnyTask = false
// 记录有障碍的 Task 所在的 Executor ID
val addressesWithDescs = ArrayBuffer[(String, TaskDescription)]()
// 按照最大本地性的原则,给 Task 提供资源
for (currentMaxLocality <- taskSet.myLocalityLevels) {
var launchedTaskAtCurrentMaxLocality = false
do {
// 给单个 TaskSet 中的 Task 提供资源
launchedTaskAtCurrentMaxLocality = resourceOfferSingleTaskSet(taskSet,
currentMaxLocality, shuffledOffers, availableCpus, tasks, addressesWithDescs)
launchedAnyTask |= launchedTaskAtCurrentMaxLocality
} while (launchedTaskAtCurrentMaxLocality)
}
if (!launchedAnyTask) {
taskSet.getCompletelyBlacklistedTaskIfAny(hostToExecutors).foreach { taskIndex =>
executorIdToRunningTaskIds.find(x => !isExecutorBusy(x._1)) match {
case Some ((executorId, _)) =>
if (!unschedulableTaskSetToExpiryTime.contains(taskSet)) {
blacklistTrackerOpt.foreach(blt => blt.killBlacklistedIdleExecutor(executorId))
val timeout = conf.get(config.UNSCHEDULABLE_TASKSET_TIMEOUT) * 1000
unschedulableTaskSetToExpiryTime(taskSet) = clock.getTimeMillis() + timeout
logInfo(s"Waiting for $timeout ms for completely "
+ s"blacklisted task to be schedulable again before aborting $taskSet.")
abortTimer.schedule(
createUnschedulableTaskSetAbortTimer(taskSet, taskIndex), timeout)
}
case None => // 立即终止
logInfo("Cannot schedule any task because of complete blacklisting. No idle" +
s" executors can be found to kill. Aborting $taskSet." )
taskSet.abortSinceCompletelyBlacklisted(taskIndex)
}
}
} else {
if (unschedulableTaskSetToExpiryTime.nonEmpty) {
logInfo("Clearing the expiry times for all unschedulable taskSets as a task was " +
"recently scheduled.")
unschedulableTaskSetToExpiryTime.clear()
}
}
if (launchedAnyTask && taskSet.isBarrier) {
// 检查有障碍的 task 是否部分启动
require(addressesWithDescs.size == taskSet.numTasks,
s"Skip current round of resource offers for barrier stage ${taskSet.stageId} " +
s"because only ${addressesWithDescs.size} out of a total number of " +
s"${taskSet.numTasks} tasks got resource offers. The resource offers may have " +
"been blacklisted or cannot fulfill task locality requirements.")
maybeInitBarrierCoordinator()
val addressesStr = addressesWithDescs
// Addresses ordered by partitionId
.sortBy(_._2.partitionId)
.map(_._1)
.mkString(",")
addressesWithDescs.foreach(_._2.properties.setProperty("addresses", addressesStr))
logInfo(s"Successfully scheduled all the ${addressesWithDescs.size} tasks for barrier " +
s"stage ${taskSet.stageId}.")
}
}
}
if (tasks.size > 0) {
hasLaunchedTask = true
}
// 返回已经获得了资源的任务列表
return tasks
}上述中的 resourceOfferSingleTaskSet 方法给单个 TaskSet 提供资源,获取 WorkerOffer 相关信息并给符合条件的 Task 创建 TaskDescription 以分配资源。
private def resourceOfferSingleTaskSet(
taskSet: TaskSetManager,
maxLocality: TaskLocality,
shuffledOffers: Seq[WorkerOffer],
availableCpus: Array[Int],
tasks: IndexedSeq[ArrayBuffer[TaskDescription]],
addressesWithDescs: ArrayBuffer[(String, TaskDescription)]) : Boolean = {
var launchedTask = false
// 到目前为止,整个应用程序中列入黑名单的节点和 Executor 已被滤除
for (i <- 0 until shuffledOffers.size) {
val execId = shuffledOffers(i).executorId
val host = shuffledOffers(i).host
if (availableCpus(i) >= CPUS_PER_TASK) {
try {
// 给符合条件的待处理 Task 创建 TaskDescription
for (task <- taskSet.resourceOffer(execId, host, maxLocality)) {
tasks(i) += task
val tid = task.taskId
taskIdToTaskSetManager.put(tid, taskSet)
taskIdToExecutorId(tid) = execId
executorIdToRunningTaskIds(execId).add(tid)
availableCpus(i) -= CPUS_PER_TASK
assert(availableCpus(i) >= 0)
if (taskSet.isBarrier) {
addressesWithDescs += (shuffledOffers(i).address.get -> task)
}
launchedTask = true
}
} catch {
case e: TaskNotSerializableException =>
logError(s"Resource offer failed, task set ${taskSet.name} was not serializable")
// 序列化异常,不为该 Task 提供资源,但是不能抛错,允许其他 TaskSet 提交
return launchedTask
}
}
}
return launchedTask
}当资源申请完后,由 Driver 向 Executor 发送启动 Task 的消息 LaunchTask,至此任务调度流程分析完毕。
private def launchTasks(tasks: Seq[Seq[TaskDescription]]) {
for (task <- tasks.flatten) {
val serializedTask = TaskDescription.encode(task)
if (serializedTask.limit() >= maxRpcMessageSize) {
Option(scheduler.taskIdToTaskSetManager.get(task.taskId)).foreach { taskSetMgr =>
try {
var msg = "Serialized task %s:%d was %d bytes, which exceeds max allowed: " +
"spark.rpc.message.maxSize (%d bytes). Consider increasing " +
"spark.rpc.message.maxSize or using broadcast variables for large values."
msg = msg.format(task.taskId, task.index, serializedTask.limit(), maxRpcMessageSize)
taskSetMgr.abort(msg)
} catch {
case e: Exception => logError("Exception in error callback", e)
}
}
}
else {
val executorData = executorDataMap(task.executorId)
executorData.freeCores -= scheduler.CPUS_PER_TASK
logDebug(s"Launching task ${task.taskId} on executor id: ${task.executorId} hostname: " +
s"${executorData.executorHost}.")
executorData.executorEndpoint.send(LaunchTask(new SerializableBuffer(serializedTask)))
}
}
}本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!