Spark 概述
本文最后更新于:2025年1月20日 中午
Spark概述
基本概念
RDD
弹性分布式数据集 ( Resilient Distrbuted Dataset),本质是一种分布式的内存抽象,表示一个只读的数据分区(Partition)集合。
DAG
有向无环图(Directed Acycle graph),Spark 使用 DAG 来反映各 RDD 间的依赖或血缘关系。
Partition
数据分区,即一个 RDD 的数据可以划分为多少个分区,Spark 根据 Partition 的数量来确定 Task 的数量。
NarrowDependency
窄依赖,即子 RDD 依赖于父 RDD 中固定的 Partition。分为 OneToOneDependency 和 RangeDependency 两种。
ShuffleDependency
宽依赖,即子 RDD 对父 RDD 中的所有 Partition 都可能产生依赖。
Job
用户提交的作业。当 RDD 及 DAG 被提交给 DAGScheduler 后,DAGScheduler 会将所有 RDD 中的转换及动作视为一个 Job(由一到多个 Task 组成)。
Stage
Job 的执行阶段。DAGScheduler 按照 ShuffleDependency 作为 Stage 的划分节点对 RDD 的 DAG 进行 Stage 划分。一个 Job 可能被分为一到多个 Stage,主要为 ShuffleMapStage 和 ResultStage 两种。
Task
具体执行任务。一个 Job 在每个 Stage 内都会按照 RDD 的 Partition 数量,创建多个 Task。Task 分为 ShuffleMapTask(ShuffleMapStage) 和 ResultTask(ResultStage)两种,对应 Hadoop 中的 Map 任务和 Reduce 任务。
Shuffle
所有 MapReduce 计算框架的核心执行阶段,用于打通 Map 任务的输出和 Reduce 任务的输入,Map 任务的中间输出结果按照指定的分区策略(例如按照 key 值哈希)分配给处理某一分区的 Reduce 任务。
基本架构
从集群部署的角度来看,Spark 由集群管理器(Cluster Manager)、工作节点(Worker)、执行器(Executor)、驱动器(Driver)、应用程序(Application)等部分组成,如下图所示。
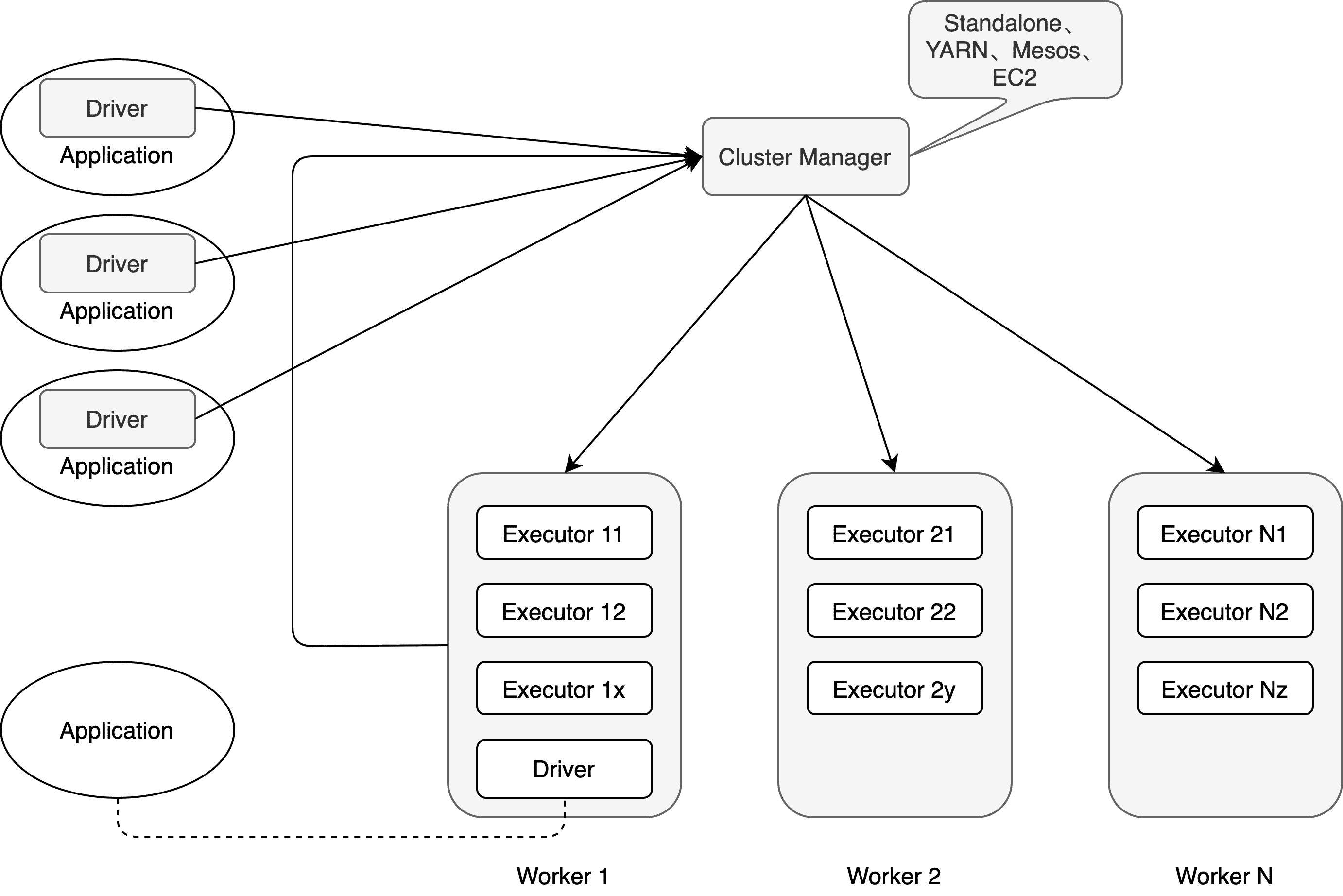
Cluster Manager
Spark 的集群管理器,主要负责对整个集群资源的分配与管理。在 YARN 模式下为 ResourceManager;在 Mesos 模式下为 MesosMaster;在 Standlone 模式下为 Master。
分配的资源属于一级分配,将各个 Worker 上的内存、CPU 等资源分配给 Application,但是并不负责对 Executor 的资源分配。
Worker
Spark 的工作节点,YARN 下由 NodeManager 替代。主要负责申请资源并创建 Executor,同时给其分配资源。在 Standalone 模式下,Master 将 Worker 上的内存、CPU 及 Executor 等资源分配给 Application 后,将命令 Worker 启动 CoarseGrainedExecutorBackend 进程(创建 Executor 实例)。
Executor
执行计算任务的一线组件,主要负责任务的执行及与 Worker、Driver 的信息同步。
Driver
Application 的驱动程序,接受用户的 SQL 请求并进行解析。Driver 可以运行在 Application 中,也可以由 Application 提交给 Cluster Manager 并由其安排 Worker 运行。
Application
表示用户的应用程序,通过 Spark API 进行 RDD 的转换和 DAG 的构建,并通过 Driver 将 Application 注册到 Cluster Manager。
模块划分
整个 Spark 主要由 Spark Core、Spark SQL、Spark Streaming、Grapx、MLlib 组成,其核心引擎部分是 Spark Core,Spark SQL 部分则支持了 SQL 及 Hive,本文也着重分析的这两部分。
Spark Core
基础设施
包括 Spark 的配置(SparkConf)、Spark 内置的 RPC 框架(早期使用的是 Akka)、事件总线(ListenerBus)、度量系统。
- SparkConf 管理 Spark 应用程序的各种配置信息。
- RPC 框架使用 Netty 实现,有同步和异步之分。
- 事件总线是 SparkContext 内部各个组件间使用事件 - 监听器模式异步调用的实现。
- 度量系统由 Spark 中的多种度量源(Source)和多种度量输出(Sink)构成,完成对整个 Spark 集群中各个组件运行期状态的监控。
SparkContext
在正式提交应用程序之前,首先需要初始化 SparkContext。其隐藏了网络通信、分布式部署、消息通信、存储体系、计算引擎、度量系统、文件服务、WebUI 等内容。
SparkEnv
Spark 的执行环境,是 Spark 中 Task 运行所必需的组件。内部封装了 RPC 环境(RpcEnv)、序列化管理器、广播管理器(BroadcastManager)、Map 任务输出跟踪器(MapOutputTracker)、存储体系、度量系统(MetricSystem)、输出提交协调器(OutputCommitCoordinator)等 Task 运行所需的各种组件。
存储体系
Spark 优先考虑使用各节点的内存作为存储,当内存不足时才会考虑使用磁盘,极大地减少了磁盘 I/O。Spark 的内存空间还提供了 Tungsten 的实现,直接操作操作系统的内存。
调度系统
主要由 DAGScheduler 和 TaskScheduler 组成,都内置在 SparkContext 中。DAGSCheduler 负责创建 Job、将 DAG 中的 RDD 划分到不同的 Stage、给 Stage 创建对应的 Task、批量提交 Task 等功能。TaskScheduler 负责按照 FIFO 或者 FAIR 等调度算法对批量 Task 进行调度、给 Task 分配资源;将 Task 发送到 Executor 上由其执行。
计算引擎
由内存管理器(MemoryManager)、Tungsten、任务内存管理器(TaskMemoryManager)、Task、外部排序器(ExternalSorter)、Shuffle 管理器(ShuffleManager)等组成。
Spark SQL
编译器 Parser
Spark SQL 采用 ANTLR4 作为 SQL 语法工具。它有两种遍历模式:监听器模式(Listener)和访问者模式(Visitor),Spark 主要采用的是后者,基于 ANTLR4 文件来生成词法分析器(SqlBaseLexer)、语法分析器(SqlBaseParser)和访问者类(SqlBaseVisitor 接口与 SqlBaseBaseVisitor 类)。
当面临开发新的语法支持时,首先改动 SqlBase.g4 文件,然后在 AstBuilder 等类中添加相应的访问逻辑,最后添加执行逻辑即可。
逻辑计划
在此阶段,SQL 语句转换为树结构形态的逻辑算子树,SQL 中包含的各种处理逻辑(过滤、裁剪等)和数据信息都会被整合在逻辑算子树的不同节点中。在实现层面被定义为 LogicalPlan 类。
从 SQL 语句经过 SparkSqlParser 解析生成 Unresolved LogicalPlan,到最后优化成为 Optimized LogicalPlan,再传递到下一个阶段用于物理执行计划的生成。
物理计划
这是 Spark SQL 整个查询过程处理流程的最后一步,与底层平台紧密相关。Spark SQL 会对生成的逻辑算子树进一步处理得到物理算子树,并将 LogicalPlan 节点及其所包含的各种信息映射成 Spark Core 计算模型的元素,如 RDD、Transformation 和 Action 等,其实现类为 SparkPlan。
References
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!